오늘의 나보다 성장한 내일의 나를 위해…
역색인
역색인: 하나의 값(term)이 들어간 문서번호를 지정하는 것
데이터 시스템에 다음과 같은 문서들을 저장한다고 가정 해 보자.

일반적으로 오라클이나 MySQL 같은 관계형 DB에서는 위 내용을 보이는 대로 테이블 구조로 저장을 한다. 만약에 위 테이블에서 Text에 fox가 포함된 행들을 가져온다고 하면 다음과 같이 Text 열을 한 줄씩 찾아 내려가면서 fox가 있으면 가져오고 없으면 넘어가는 식으로 데이터를 가져 올 것이다.

전통적인 RDBMS에서는 위와 같이 like 검색을 사용하기 때문에 데이터가 늘어날수록 검색해야 할 대상이 늘어나 시간도 오래 걸리고, row 안의 내용을 모두 읽어야 하기 때문에 기본적으로 속도가 느리다. Elastic Search는 데이터를 저장할 때 다음과 같이 역 인덱스(inverted index)라는 구조를 만들어 저장한다.
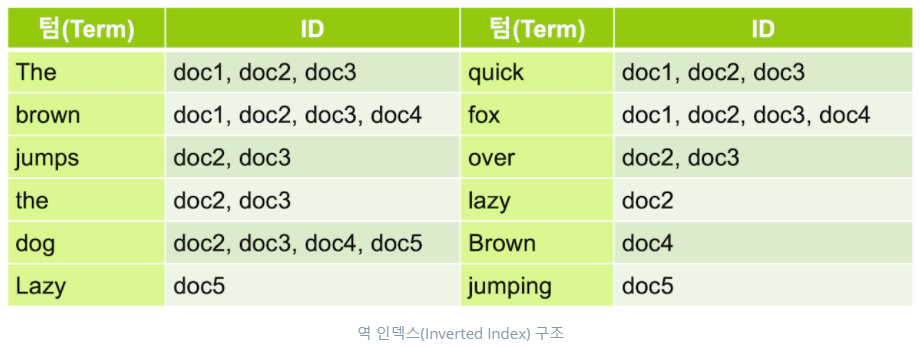
이 역인덱스는 책에 맨 뒤에 있는 주요 키워드에 대한 내용이 몇 페이지에 있는지 볼 수 있는 찾아보기 페이지에 비유할 수 있다. Elasticsearch에서는 추출된 각 키워드를 텀(term)이라고 부른다. 이렇게 역인덱스가 있으면 fox를 포함하고 있는 document의 id를 바로 얻어올 수 있다.

Elasticsearch는 데이터가 늘어나도 찾아가야 할 행이 늘어나는 것이 아니라 역인덱스가 가리키는 id의 배열값이 추가되는 것 뿐이기 때문에 큰 속도의 저하 없이 빠른 속도로 검색이 가능하다. 이런 역인덱스를 데이터가 저장되는 과정에서 만들기 때문에 Elasticsearch는 데이터를 입력할 때 저장이 아닌 색인을 한다고 표현한다.
 기존의 전톡적인 검색 방식
기존의 전톡적인 검색 방식
 1. WHERE 검색방식
1. WHERE 검색방식
SELECT * FROM 'M_DOCUMENT' WHERE 'bookname' = 'Buying a Home'
위 경우 검색어와 정확히 일치하는 문서만 선택된다. 즉, 문서 결과를 거의 얻지 못한다. 그리고 선택되는 문서 수 자체가 거의 없다.
2. WHERE LIKE 검색 방식
SELECT * FROM `M_DOCUMENT` WHERE `bookname` LIKE '%Buying a Home%'
이 경우 검색어가 문서내용(bookname 필드)에 포함되어 있는 경우 선택이 된다. 1번 방식보다 진화한 방식이지만 여전히 해당 문장이 정확히 일치하는 경우가 적기 때문에 결과를 거의 얻지 못한다.
3. Whitespace tokenizer AND 검색방식
사용자의 쿼리를 4. Whitespace로 쪼개서 AND 검색을 실시한다.
SELECT * FROM `M_DOCUMENT` WHERE `bookname`
LIKE '%Buying%' AND `bookname` LIKE '%a%' AND `bookname` LIKE '%HOME%'
4. Whitespace tokenizer OR 검색방식
사용자의 쿼리를 Whitespace로 쪼개서 OR 검색을 실시한다.
SELECT * FROM `M_DOCUMENT` WHERE `bookname`
LIKE '%Buying%' OR `bookname` LIKE '%a%' AND `bookname` LIKE '%HOME%'
문서내용(bookname 필드)에 사용자 검색어 중 하나라도 포함되는 경우를 찾는다. 사용자가 원하는 문서를 찾아준다는 점에서 매우 우수한 검색방식이다. 하지만 어느 하나의 단어만 포함되도 되기에 전혀 관계가 없는 문서도 결과물(result-set)로 추출된다.
전통적인 검색방식의 가장 큰 문제점은 전체 글의 content 필드를 모두 읽어들여서 검색어의 포함여부를 확인한다는 것이다.
따라서 결과를 얻기까지 많은 노력과 시간이 필요하게 된다.
이것은 인덱싱이 되지 않는다고 하는데 위의 DB 쿼리 구문은 모든 글에 대해서 ‘content’ 항목값을 읽은 후에 찾아야하고 이보다 더 나은 방법은 없다는 뜻이다.
4번의 방식은 현재 한국 내 커뮤니티에서 가장 많이 사용하고 있는 검색방식이다.
따라서 국내 커뮤니티 검색엔진에서 좋은 결과를 얻고자 한다면 키워드 입력방식을 사용해야 한다.
예를 들어 “집을 살때 필요한 서류”를 검색하고 싶으면 “집 서류” 라고 검색해야 가장 훌륭한 결과물을 얻어낼 수 있다.
SELECT * FROM `M_DOCUMENT` WHERE `bookname` LIKE ‘%집%’ OR `bookname` LIKE ‘%서류%’
4번이 정말 좋은 방식이긴한데 몇 가지 단점이 있다.
- 의미없는 결과 값도 나온다.
- 검색 대상이 누적되면서(100만개 정도의 big data가 되면서) 검색부하가 엄청 오래 걸림
예를 들어 4번과 같은 쿼리를 100만개 정도의 big data라고 했을 때 검색을 진행하면 검색부하가 엄청 오래 걸린다.
역색인의 장점
앞서 간단하게 역색인과 기존의 전통적인 검색 방식에 대해서 살펴보았다. 역색인을 지원하는 일라스틱 서치에 대해 좀 더 알아보자.
Inverted Index
기존의 데이터베이스가 하나의 구분자(Primary Key)가 여러 필드를 지정하고 있었다면 Inverted Index에서는 하나의 값(Term)이 해당 Term이 들어간 document id 를 지정하고 있습니다.
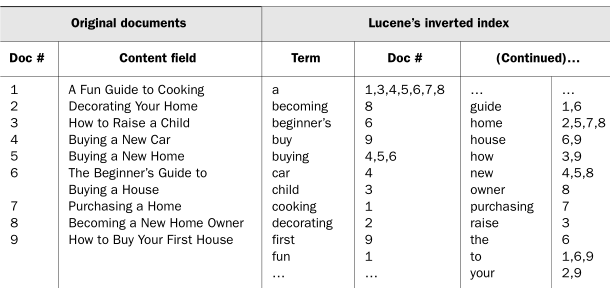
1~9 document 데이터를 분석해서 테이블을 구성한다. 오른쪽 inverted index table을 보면, becoming home이라고 검색하면 becoming과 home으로 나눈 후에 빠르게 (8), (2,5,7,8)이라는 결과가 반환이 되고 8이 가장 유사한 결과물이라고 알게 된다.
인덱싱을 하기 때문에 탐색 속도가 매우 빠르다.
Inverted Index with Term Position
이 기능은 검색 결과를 향상시키기 위한 것이다.
단어 값(Term)이 추가 정보를 지정할 수 있게 된다. 여기서는 위치정보를 말한다.
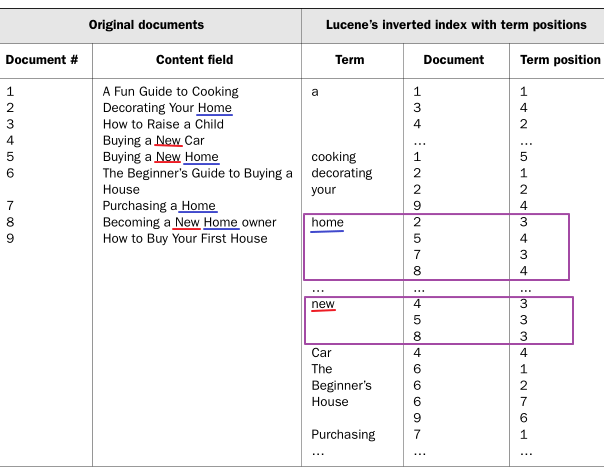
예시로 사용자가 new home을 검색했다고 가정하면 위의 그림에 따라 5번과 8번 document를 반환하게 된다. 5번과 8번이 두 단어를 모두 포함하는 document 일뿐 아니라, new 다음에 home이 나타나는 문서임을 알 수 있다. (Term position 순서 비교)
단어가 연속되는지 (new home) 여부를 빠르게 파악이 가능하고 단어(Term) 사이의 값을 찾을 수도 있다. 이것을 활용해 new home, new brand home, new super cheap home 등이 결과에 나올 수 있게 된다.(Proximity Search)
정리
문서내용(bookname 필드)에 사용자 검색어의 모든 단어가 포함된 경우를 찾는다. 이전 방식과 비교해서 상당히 많이 향상된 결과를 보여주지만 해당 단어가 모두 포함된 문서가 아니면 결과에 포함되지 않는다.
Whitespace tokenizer OR 검색방식
SELECT * FROM `M_DOCUMENT` WHERE `bookname`
LIKE '%Buying%' OR `bookname` LIKE '%a%' AND `bookname` LIKE '%HOME%'
문서내용(bookname 필드)에 사용자 검색어 중 하나라도 포함되는 경우를 찾는다. 사용자가 원하는 문서를 찾아준다는 점에서 매우 우수한 검색방식이다. 하지만 어느 하나의 단어만 포함되도 되기에 전혀 관계가 없는 문서도 결과물로 추출된다.
Traditional SQL에서 LIKE 검색이 INDEX 기능을 이용할 수 없다는 단점이 있어서, 그 문제를 극복하기 위해서 단어(Term)로 인덱싱을 하는 Inverted Index 방식이 고안되었다.
기존의 데이터베이스가 하나의 구분자(Primary Key)가 여러 필드를 지정하고 있었다면 Inverted Index에서는 하나의 값(Term)이 해당 Term이 들어간 document id를 지정한다.
만약 DB에서 “Trade”라는 문구가 포함된 문자열을 찾으려고 한다면 SQL에서는 %Trade%라고 명확히 입력해야 검색이 가능하다.
trade, TRADE, trAde…등의 문자열은 하나하나 명시하기 전에는 찾을 수 없다. 역색인을 활용하면 대소문자 구분 없이 어떤 문구가 들어와도 찾을 수 있음
- RDB는 행을 기반으로 데이터를 저장 그에 반해 엘라스틱서치는 단어를 기반으로(역인덱스) 저장한다.
-
RDB는 데이터 수정, 삭제의 편의성과 속도 면에서 강점이 있지만 다양한 조건의 데이터를 검색하고 집계하는 데에는 구조적인 한계가 있다
- document 개수만큼 특정 단어가 있는지 확인을 반복해야 하기 때문에 많은 수의 document가 있을 경우 비효율적이다.
- 반면 일라스틱서치는 특정 단어가 어디에 저장되어 있는지 이미 알고 있어 모든 document를 검색할 필요는 없다.
- 다만 수정과 삭제는 엘라스틱서치 내부적으로 굉장히 많은 리소스가 소요된다.
