오늘의 나보다 성장한 내일의 나를 위해…
 Clustered Index vs Non-Clustered Index
Clustered Index vs Non-Clustered Index
이번에는 인덱스의 종류인 클러스터 인덱스와 넌 클러스터 인덱스에 대해서 알아보자.
일단 인덱스란 데이터를 빠르게 검색할 수 있게 해주는 객체이다.
컬럼을 정렬한 후에 데이터를 빠르게 찾을 수 있도록 도와주는 역할을 한다.
인덱스를 생성한다고 무조건 데이터를 빠르게 검색할 수 있는 것은 아니다.
인덱스를 무작정 생성하는 것은 좋은 방법이 아닌 것이다.
중요한 것은 인덱스를 생성할 때 테이블의 용도를 정확하게 파악하는 것이다.
용도에 따라서 적절한 컬럼으로 Clustered Index와 Non-Clustered Index를 구성해야 한다.
 클러스터 인덱스
클러스터 인덱스
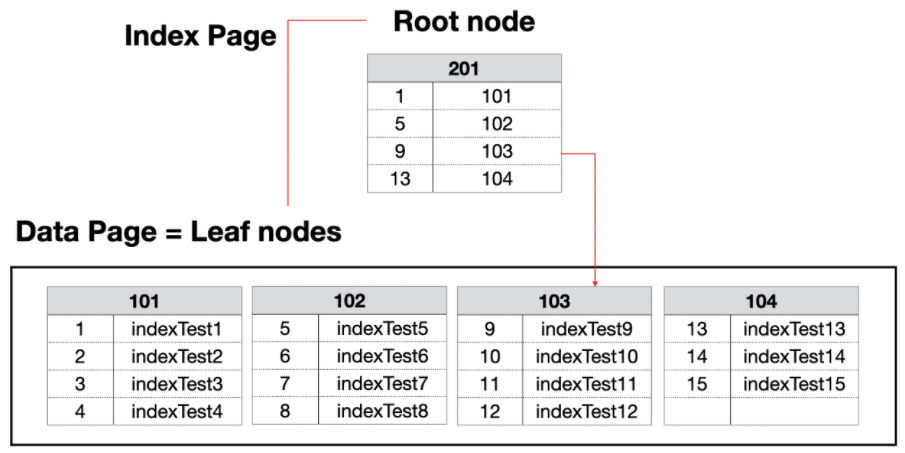
클러스터 인덱스는 데이터페이지 자체가 인덱스 키 값에 의해 물리적으로 정렬이 된다.
즉, 데이터페이지는 리프 레벨이라고 볼 수 있다.
아래와 같은 SQL를 실행해서 클러스터 인덱스를 구성해보자
USE tempdb
CREATE TABLE clusterExTable (id int NOT NULL,value nvarchar(20) NOT NULL);
INSERT INTO clusterExTable VALUES (1,'indexTest1');
INSERT INTO clusterExTable VALUES (15,'indexTest15');
INSERT INTO clusterExTable VALUES (7,'indexTest7');
INSERT INTO clusterExTable VALUES (8,'indexTest8');
INSERT INTO clusterExTable VALUES (4,'indexTest4');
INSERT INTO clusterExTable VALUES (2,'indexTest2');
INSERT INTO clusterExTable VALUES (3,'indexTest3');
INSERT INTO clusterExTable VALUES (11,'indexTest7');
INSERT INTO clusterExTable VALUES (9,'indexTest8');
INSERT INTO clusterExTable VALUES (14,'indexTest14');
INSERT INTO clusterExTable VALUES (5,'indexTest5');
INSERT INTO clusterExTable VALUES (10,'indexTes10');
INSERT INTO clusterExTable VALUES (13,'indexTest13');
INSERT INTO clusterExTable VALUES (6,'indexTest6');
INSERT INTO clusterExTable VALUES (12,'indexTest12');
ALTER TABLE clusterExTable ADD CONSTRINT PK_clusterExTable_id PRIMARY KEY(id);
클러스터형 인덱스를 구성하려면 행 데이터를 해당 열로 정렬한 후에 루트 페이지를 만들게 된다. 즉 데이터 페이지는 리프 노드와 같은 것을 확인할 수 있다.
 특징
특징
- 테이블 당 1개만 허용
- 기본 키 설정시 자동으로 만들어짐
- 테이블 자체가 인덱스 (클러스터 인덱스를 기준으로 테이블을 정렬하기 때문에 인덱스 페이지가 없다)
- 데이터 입력, 수정, 삭제 시 항상 정렬을 유지함
- 기본적으로 접근 성능이 좋음
넌클러스터 인덱스
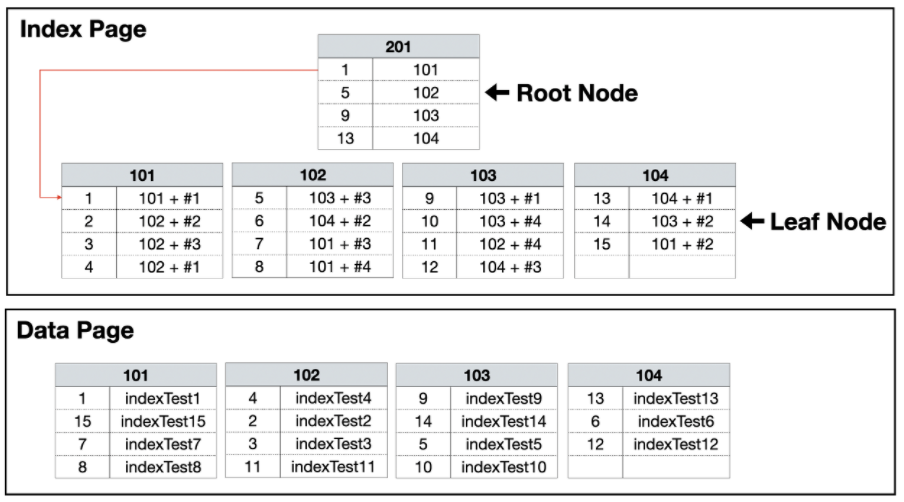
넌 클러스트형 인덱스는 데이터 페이지를 건들지 않고, 별도의 장소에 인덱스 페이지를 생성한다.
우선 인덱스 페이지의 리프 페이지에 인덱스로 구성한 열을 정렬하고 데이터 위치 포인터를 생성한다.
데이터의 위치 포인터는 클러스터형 인덱스와 달리 ‘페이지 번호 + #오프셋’이 기록되어 바로 데이터 위치를 가리킨다.
아래 그림을 예시로 들어보자.
indexTest2로 보자면 102번 페이지의 두 번째(#2)에 데이터가 있다고 기록하게 된다.
그러므로 이 데이터 위치 포인터는 데이터가 위치한 고유한 값이 된다.
특징
- 테이블 당 최대 240개 생성 가능
- 인덱스 페이지를 별도로 저장
- 테이블 자체는 되지 않고, 인덱스 페이지에만 정렬
- 성능 증가는 정말 “Case By Case”
활용
클러스터 인덱스
쿼리를 기준으로 예를 들어보자
SELECT year(hire_date), count(*)
FROM employees
WHERE hire_date >= '1997-01-01'
GROUP BY year(hire_date);
조건절에 hire_date가 있고, 범위 탐색이다. 이 경우 hire_date에 클러스터 인덱스를 적용하면 성능이 엄청나게 향상된다.
여기서 WHERE 절만 빼보자.
SELECT year(hire_date), count(*)
FROM employees
GROUP BY year(hire_date);
여기서도 마찬가지로 hire_date에 인덱스를 건다면 어떻게 될까?
성능 향상에 도움이 안되거나, 데이터가 많아지는 경우 오히려 느려진다.
스캔 방식을 생각해야 한다.
클러스터 인덱스가 없는 경우 기본적으로 Heap 테이블 스캔이(클러스터 인덱스가 없는 테이블의 겨우 데이터는 추가된 순서대로 쌓이니까 힙이라 한다. 즉, 테이블 전체를 스캔하는 것이다.) 이루어진다.
특징
- 인덱싱되지 않은 상태
- 정렬의 기준이 없음
- 데이터 페이지 내의 행들 간의 순서가 없음
- 클러스터형 인덱스가 없는 테이블
장단점
- INSERT에 유리, 순서없이 그냥 페이지 빈 곳에 새 데이터를 추가하면 됨 - SELECT에 불리. 원하는 데이터를 찾기 위해서는 모든 데이터를 스캔해보아야 함.(Table Scan)
클러스터 인덱스가 있는 경우에는 클러스터 인덱스 스캔이 이루어진다.
하지만 조건절이 없으므로 무식하게 다 읽는건 Heap 테이블 스캔이 빠르다.
넌클러스터 인덱스
위의 예시와 같은 쿼리이다.
SELECT year(hire_date), count(*)
FROM employees
WHERE hire_date >= '1997-01-01'
GROUP BY year(hire_date);
여기서 hire_date에 넌클러스터 인덱스를 건다면 어떻게 될까?
놀랍게도 클러스터 인덱스를 걸었을 때보다 더 빠르다.
그 이유는 넌클러스터 인덱스가 탐색 범위에 포함되었기 때문에 옵티마이저에서는 인덱스 스캔이 아닌 Non-Clustered Index Seek 방식을 선택하기 때문이다.
Index Scan은 인덱스의 모든 행을 인덱스 순서로 읽는 반면에 Index Seek은 필터 기준에 따라 일치하는 행이나 한정된 행만 찾으려고 리프 노드를 거치기 때문에 논리적 읽기 수가 훨씬 감소한다
Index Scan은 Leaf Level의 첫번째 페이지부터 데이터 검색을 수행하는 방법. 일반적으로 얘기하는 Table Scan과 동일한 방법이지만, 그 대상이 Leaf Level의 인덱스 페이지라는 것이다.
정리
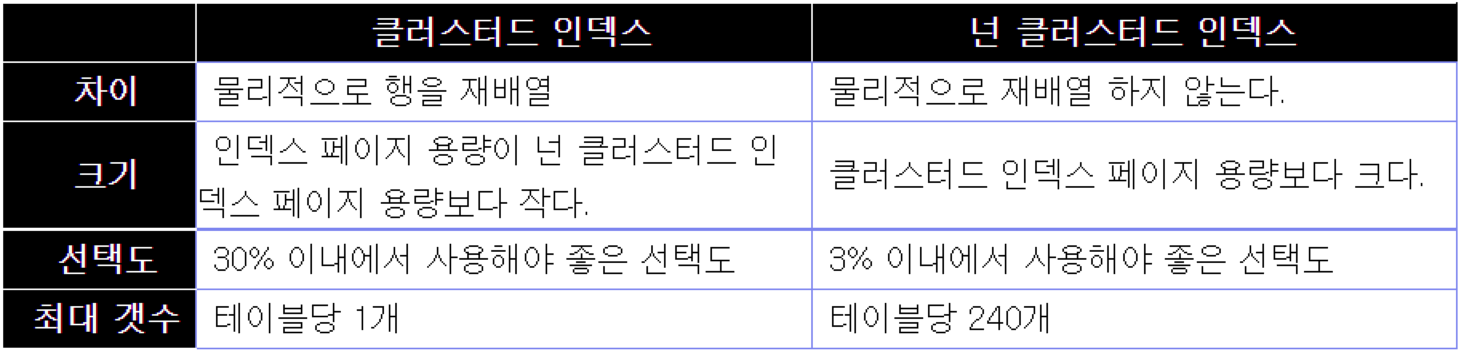
여기서 물리적으로 행을 재배열한다는 것을 알아보자
아래와 같은 SQL이 있다.
CREATE TABLE TBL_CLUSTERED_TEST (
LOG_DATE CHAR(8) NOT NULL,
MEDIA_ID CHAR(1) NOT NULL,
PROCEEDS DOUBLE DEFAULT NULL,
PRIMARY KEY (LOG_DATE,MEDIA_ID)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
5개의 테스트 데이터를 저장해 본다.
INSERT INTO TBL_CLUSTERED_TEST (LOG_DATE, MEDIA_ID, PROCEEDS) VALUES ('20130618', 'A', 1000);
INSERT INTO TBL_CLUSTERED_TEST (LOG_DATE, MEDIA_ID, PROCEEDS) VALUES ('20130619', 'A', 1000);
INSERT INTO TBL_CLUSTERED_TEST (LOG_DATE, MEDIA_ID, PROCEEDS) VALUES ('20130619', 'C', 2000);
INSERT INTO TBL_CLUSTERED_TEST (LOG_DATE, MEDIA_ID, PROCEEDS) VALUES ('20130619', 'B', 1000);
INSERT INTO TBL_CLUSTERED_TEST (LOG_DATE, MEDIA_ID, PROCEEDS) VALUES ('20130613', 'B', 3000);
해당 테이블을 select 하면 insert 되어 있는 순서대로 데이터가 누적되어 있을까?
아니다. LOG_DATE, MEDIA_ID는 클러스터드 인덱스로 생성이 되어 있기 때문에 물리적으로 LOG_DATE를 정렬한 후 MEDIA_ID를 정렬하게 된다.
물리적으로 정렬을 한다는 말은 이를 두고 하는 말이다. 실제 DB의 데이터파일에 정렬이 되어 있는 상태로 디스크에 저장이 된다는 것이다.
테이블 조회를 해보면 아래와 같이 데이터가 정렬되어 있는 것을 확인할 수 있다. (6월 13일 데이터가 가장 위에 있음)
mysql> select * from tbl_clustered_test;
+----------+----------+----------+
| LOG_DATE | MEDIA_ID | PROCEEDS |
+----------+----------+----------+
| 20130613 | B | 3000 |
| 20130618 | A | 1000 |
| 20130619 | A | 1000 |
| 20130619 | B | 1000 |
| 20130619 | C | 2000 |
+----------+----------+----------+
그럼 넌 클러스터드 인덱스는?
일반적으로 조회문 성능 향상을 위해서 넌 클러스터드 인덱스를 생성하여 사용하곤 한다.
허나, 이 인덱스는 클러스터드인덱스와는 다르게 물리적으로 데이터가 정렬되어 저장되지 않는다.
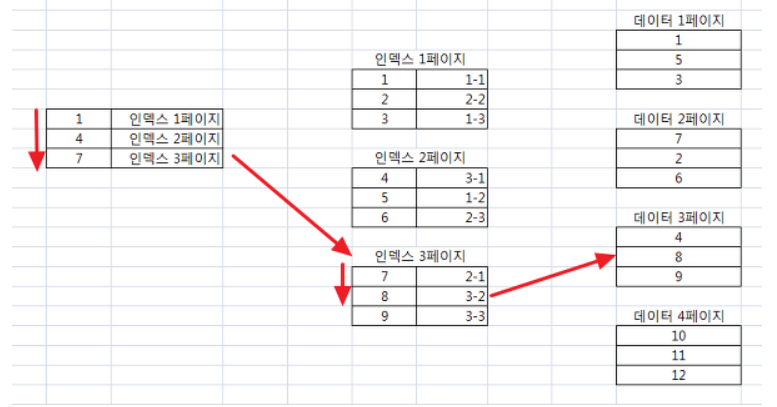
위 사진의 넌클러스터 인덱스에서 데이터 페이지에 있는 데이터들은 정렬이 되지 않은 상태인 것을 볼 수 있다.
읽어보면 좋은 사이트
