오늘의 나보다 성장한 내일의 나를 위해…
 NoSQL
NoSQL
NoSQL은 RDBMS의 형태가 아닌 일관성 모델(비관계형 모델)을 이용하는 데이터 저장을 말하는 것이다. NoSQL 데이터베이스는 기존의 관계형 데이터베이스보다 더 융통성 있는 데이터 모델을 사용하고 데이터의 저장 및 검색을 위한 특화된 메커니즘을 제공한다.
이를 통해 NoSQL 데이터베이스는 단순 검색 및 추가작어베 있어서 매우 최적화된 키 값 저장 기법을 사용하여 응답속도나 처리효율 등에 있어서 매우 뛰어난 성능을 나타낸다.
 NoSQL의 특징
NoSQL의 특징
1) 관계형 모델을 사용하지 않으며 테이블 간 연결해서 조회할 수 있는 조인 기능이 없다.
2) 데이터 조회를 위해 직접 프로그래밍하는 등의 비SQL 인터페이스를 통한 데이터 접근
3) 대부분 여러 데이터베이스 서버를 묶어서(클러스터링) 하나의 데이터베이스를 구성
4) 관계형 데이터베이스에서는 지원하는 데이터 처리 완결성(Trascation, ACID 지원)이 보장되지 않음
5) 데이터의 스키마와 속성들을 다양하게 수용하고 동적으로 정의(Schemaless)
6) 데이터베이스의 중단없는 서비스와 자동 복구 기능 지원
7) 대다수의 제품이 Open Source로 제공
8) 대다수의 제품이 고확장성, 고가용성, 고성능 특징을 가진다.
9) 관계형 데이터베이스보다 훨씬 다양한 방식으로 빠르게 바뀌는 대량의 비정형 데이터를 처리할 수 있음
정리하면 NoSQL은 초고용량 데이터 처리등 성능에 특화된 목적을 위해 비 관계형 데이터 저장소에 비 구조적인 데이터를 저장하기 위한 분산저장 시스템이라고 볼 수 있다.
대표적인 NoSQL
-
key-value Database
- Riak, Redis, Voldmort
-
Document Database
- MongoDB, CouchDB
-
BigTable Database
- Hbase, Casandra
-
Graph Database
- Sones, AllegroGraph
NoSQL의 장점
- RDBNS에 비해 저렴한 비용으로 분산 처리와 병렬 처리가 가능
- 비정형 데이터 구조 설계로 설계 비용이 감소
- 관계형 데이터베이스의 relation과 join 구조를 linking과 embedded로 구현하여 성능이 빠름
-
Big Data 처리에 효과적
- 많은 서버로 확장이 가능(데이터 중복이 생기더라도 테이블을 정규화 시키지 않아도 큰 테이블에 담아 저장)
- 가변적인 구조로 데이터 저장이 가능
- Scale out 구조를 채댁하여 서버 확장에 용이하며 더 많은 데이터를 저장
- Document based(Schema-less) 구조로 데이터 모델의 유연한 변화가 가능
- json 구조로 RDBMS 테이블 구조에 비해 데이터를 직관적으로 파악
- Auto Sharding을 지원
단일의 논리적 데이터셋을 다수의 데이터베이스에 쪼개고 나누는 방법이다. 이런 방법으로 데이터베이스 시스템의 클러스터에서 큰 데이터셋을 저장하고 추가적인 요청을 처리할 수 있다. 샤딩은 데이터셋이 단일 데이터베이스에서 저장하기에 너무 클 때 필수적으로 사용된다.
NoSQL의 단점
- 데이터 업데이트 중 장애가 발생하면 데이터 손실 발생 가능
- 많은 인덱스를 사용하려면 충분한 메모리가 필요. 인덱스 구조가 메모리에 저장
- 복잡한 join은 어려움(다양하고 복잡한 데이터 쿼리), document based이기 때문
- NoSQL은 sharding 방식을 사용해서 큰 테이블을 여러 서버에 나누어 저장한다. fault tolerancy를 위해 데이터는 두개 이상의 서버에 저장된다. 어떤 데이터가 update 되었을 때, NoSQL은 중복 저장된 서버들에 해당 update가 적용되기까지는 시간이 걸린다.
- RDBMS는 모든 서버를 update 되기전까지는 해당 데이터 또는 테이블에 lock을 걸어 읽기 금지를 한다. 따라서 데이터에 대한 일관성이 보장된다. 하지만 NoSQL에서는 lock을 하게 될 경우 느려지므로 RDBMS와 같은 lock을 하지 않는다.
- 데이터 일관성이 항상 보장되지 않는다.
NoSQL의 종류
 Key-Value Database
Key-Value Database
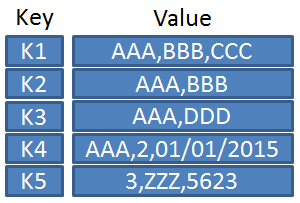
기본적인 패턴으로 KEY-VALUE 하나의 묶음(Unique)으로 저장되는 구조로 단순한 구조이기에 속도가 빠르며 분산 저장시 용이하다. Key 안에 (COLUMN, VALUE) 형태로 된 여러 개의 필드, 즉 COLUMN FAMILIES을 갖는다.
주로 SERVER CONFIG, SESSION CLUSTERING등에 사용되고 엑세스 속도는 빠르지만, SCAN에는 용이하지 않다.
Ex) Redis, Oracle NoSQL Database, VoldeMort
Wide-Column Database
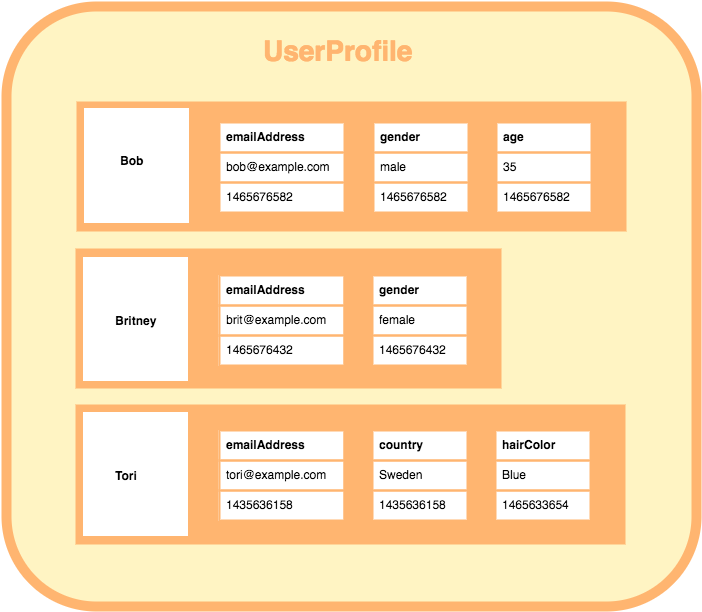
행마다 키와 해당 값을 저장할 때마다 각각 다른 값의 다른 수의 스키마를 가질 수 있다.
위 그림을 참고하면 사용자의 이름(key)에 해당하는 값에 스키마들이 각각 다름을 볼 수 있다.
이러한 구조를 갖는 WIDE COlUMN DATABASE는 대량의 데이터 압축, 분산처리, 집계 쿼리(SUM, COUNT, AVG)및 쿼리 동작 속도 그리고 확장성이 뛰어난 것이 대표적 특징이라 할 수 있다.
Ex) Hbase, GoogleBigTable, Vertica
Document Database
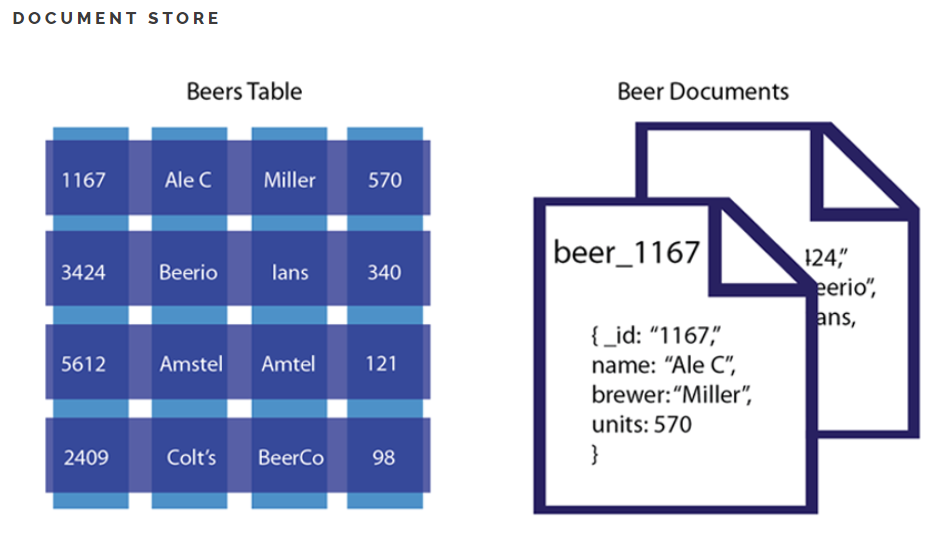
테이블의 스키마가 유동적, 즉 레코드마다 각각 다른 스키마를 가질 수 있다. 보통 XML, JSON과 같은 DOCUMENT를 이용해 레코드를 저장한다.
트리형 구조로 레코드를 저장하거나 검색하는 데 효율적이다.
Ex) MongoDB, CouchDB, Azure Cosmos DB
Graph Database
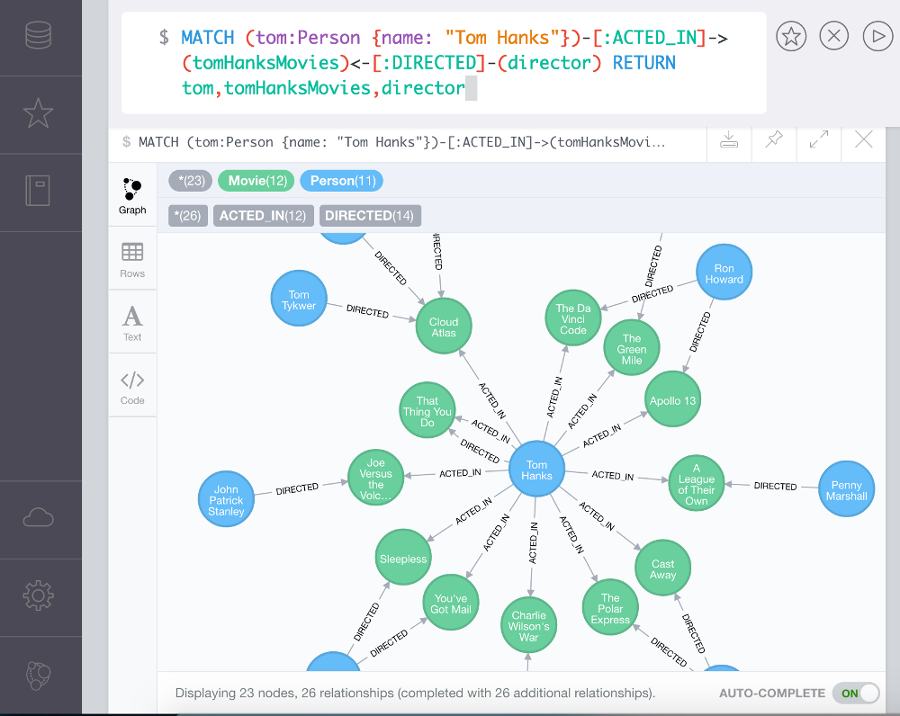
데이터를 노드로(그림에서 파란, 녹색 원) 표현하며 노드 사이의 관계를 엣지(그림에서 화살표)로 표현한다.
일반적으로 RDBMS보다 성능이 좋고 유연하며 유지보수에 용이한 것이 특징이다.
Social networks, Network diagrams 등에 사용할 수 있다.
Ex) Neo4j, BlazeGraph, OrientDB
