피곤한데 커피 한잔만 마시고 시작해보자..
Kubernetes와 Mysql Workbench 연동하기
여기서는 교육용 및 소규모 환경에서 사용하기 좋은 베이그런트(Vagrant)를 사용하고 베이그런트와 호환성이 좋은 버추얼박스(VirtualBox)를 사용해서 진행한다.


Vagrantfile 설정은 밑에 링크 달아놓은 이전 게시물을 참고
위 링크에 들어가면 나오는 Vagrantfile과 스크립트들을 한 디렉토리에 넣고 vagrant up를 하게 되면 아래 사진과 같이 virtual box에 4개의 가상 머신이 생기는 것을 확인할 수 있다.

이제 Superputty로 m-k8s를 접속한다.
그리고 우리는 쿠버네티스 공식 문서에서 mysql를 배포하는 방법에 대해서 따라한다.
이 사이트에서는 쿠버네티스 클러스터에서 퍼시스턴트볼륨(PersistentVolume)과 디폴로이먼트(Deployment)를 사용하여, 단일 이스턴스 스테이트풀 애플리케이션을 실행하는 방법을 보인다. 해당 애플리케이션은 MYSQL이다.
그 이전에 퍼시스턴트볼륨과 스테이트풀에 대한 개념을 간단하게 알아보자.
그러나 스테이트풀(stateful) 애플리케이션은 애완동물과 같습니다. 애완동물이 죽었을 때 새 애완동물을 바로 살 수 없고, 주변 사람들도 금방 알아차릴 것이기 때문입니다. 잃어버린 애완동물을 대체하기 위해선 이전 애완동물과 생김새나 행동이 완전히 똑같은 새로운 애완동물을 찾아야 하는데, 이는 애플리케이션의 경우 새 인스턴스가 이전 인스턴스와 완전히 같은 상태와 아이덴티티를 가져야 함을 의미합니다.
레플리카셋이나 레플리케이션 컨트롤러로 관리되는 파드는 가축과 같습니다. 이 파드들은 stateless로 언제든지 새로운 파드로 교체될 수 있습니다. 반면 스테이트풀셋으로 관리되는 파드는 stateful해서 새로운 파드로 교체될 때 동일한 이름, 네트워크 아이덴티티, 상태 그대로 다음 노드에서 되살아납니다.
목적
쿠버네티스 클러스터가 일단 필요하고 kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정이 되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다.
쿠버네티스 디폴이먼트를 생성하고 퍼시스턴트볼륨클레임을 사용하는 기존 퍼시스턴트볼륨에 연결하여 스테이트풀 애플리케이션을 실행할 수 있다. 아래 YAML 파일은 MySQL을 실행하고 퍼시스턴트 볼륨클레임을 참조하는 디폴로이먼트를 기술한다. 이 파일은 /var/lib/mysql에 대한 볼륨 마운트를 정의한 후에, 20G의 볼륨을 요청하는 퍼시트턴트볼륨클레임을 생성한다. 이 클레임은 요구 사항에 적합한 기존 볼륨이나 동적 프로비저너에 의해서 충족된다.
mysql-deployment.yaml
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
ports:
- port: 3306
selector:
app: mysql
clusterIP: None
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
strategy:
type: Recreate
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: mysql:5.6
name: mysql
env:
# Use secret in real usage
- name: MYSQL_ROOT_PASSWORD
value: password
ports:
- containerPort: 3306
name: mysql
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
하나 하나 씩 뭔지 알아가보자
mysql-deployment.yaml
#apiVersion: API 버전을 명시한다
#이 오브젝트를 생성하기 위해 사용하고 있는 쿠버네티스 API 버전이 어떤 것인지
#명시한다.
apiVersion: v1
#어떤 종류의 오브젝트를 생성하고자 하는지 명시한다.
kind: Service
#이름 문자열, UID, 그리고 선택적인 네임스페이스를 포함하여
#오브젝트를 유일하게 구분지어 줄 데이터이다.
#서비스 이름(name)은 mysql이다.
metadata:
name: mysql
#오브젝트에 대해 어떤 상태를 의도하는지 명시한다.
spec:
#포트 3306을 사용한다.
ports:
- port: 3306
#(.spec.selector)디플로이먼트가 관리할 파드를 찾는 방법을 정의한다.
#이 사례에서는 파드 템플릿(아래 명시된 template)에 정의된 레이블(app:mysql)을
#선택한다.
selector:
app: mysql
#서비스 프록시가 사용하는 IP 주소,
clusterIP: None
---
#apiVersion: API 버전을 명시한다
#이 오브젝트를 생성하기 위해 사용하고 있는 쿠버네티스 API 버전이 어떤 것인지
#명시한다. apps/v1에서는 .spec.selector 와 .metadata.labels 이
#설정되지 않으면 .spec.template.metadata.labels 은 기본 설정되지 않는다.
#그래서 이것들은 명시적으로 설정되어야 한다. 또한 apps/v1 에서는
#디플로이먼트를 생성한 후에는 .spec.selector 이 변경되지 않는 점을 참고한다.
apiVersion: apps/v1
#어떤 종류의 오브젝트를 생성하고자 하는지 명시한다.
kind: Deployment
#이름 문자열, UID, 그리고 선택적인 네임스페이스를 포함하여
#오브젝트를 유일하게 구분지어 줄 데이터이다.
#디플로이먼트 이름(name)은 mysql이다.
#차후에 이 디플로이먼트를 delete할 때 이 이름으로 지운다.
metadata:
name: mysql
#오브젝트에 대해 어떤 상태를 의도하는지 명시한다.
spec:
#(.spec.selector)디플로이먼트가 관리할 파드를 찾는 방법을 정의한다.
#이 사례에서는 파드 템플릿(아래 명시된 template)에 정의된 레이블(app:mysql)을 선택한다.
selector:
matchLabels:
app: mysql
#파드 교체 전략을 지정한다. Recreate의 경우 기존 파드를 모두
#삭제한 다음 새로운 파드를 생성하는 방법이다. (이 방식은 무중단이 아니다)
#기본값은 RollingUpdate이다. RollingUpdate은 Pod를 하나씩 죽이고
#새로 띄우면서 순차적으로 교체하는 방법이다.
strategy:
type: Recreate
template:
#파드는 .metadata.labels 필드를 사용해서
#app: mysql레이블을 붙인다
metadata:
labels:
app: mysql
#.template.spec 필드는 파드가 도커 허브의
#mysql:5.6 이미지를 실행하는
#mysql 컨테이너 1개를 실행하는 것을 나타낸다
#컨테이너 1개를 생성하고 .spec.template.spec.containers[0].name 필드를
#사용해서 mysql 이라는 이름을 붙인다.
#즉 컨테이너의 이름이 mysql이 된다. describe deployment 명령어로 확인 가능
#파드는 여러 개의 컨테이너를 가질 수 있는데 여기서는 하나만 선언한 것
spec:
containers:
#docker image는 docker registry에서 pull을 받아 오게 되는데,
#docker registry가 명시되어 있지 않다면 docker 공식 public registry인
#docker hub(https://hub.docker.com)에서 해당 image를 가져오게 됩니다.
# 만약 private docker registry를 사용한다면 docker image 이름 앞에 해당
#url을 명시해 줘야 하며 k8s에서는 remote docker registry와 통신은 http가
#아닌 https로만 하게 되어 있어서 private docker registry에 반드시 TLS 인증서를 설치해둬야 합니다.
- image: mysql:5.6
#container name은 mysql이고 동일한 pod 내에서 유일한 이름을 가져야 합니다.
name: mysql
#환경변수를 정의한다.
env:
# 여기서는 mysql의 루트 비밀번호를 변경하는데 그 비밀번호를 password로 지정한다.
- name: MYSQL_ROOT_PASSWORD
value: password
#컨테이너 포트 지정
ports:
- containerPort: 3306
name: mysql
#볼륨을 사용하려면, .spec.volumes에서 파드에 제공할 볼륨을 지정하고
#.spec.containers[*].volumeMounts의 컨테이너에 해당 볼륨을 마운트할 위치를
#선언한다.
volumeMounts:
#볼륨 이름
- name: mysql-persistent-storage
#컨테이너에 해당 볼륨을 마운트할 위치
mountPath: /var/lib/mysql
#PVC로 생성된 볼륨을 마운트하기 위해서 mysql-pv-claim이라는 이름을 사용한다.
volumes:
#볼륨 이름
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
이제 PV를 설정하는 yaml 파일을 살펴보자
mysql-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: mysql-pv-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
이것도 하나하나 살펴보자.
mysql-pv.yaml
#apiVersion: API 버전을 명시한다
#이 오브젝트를 생성하기 위해 사용하고 있는 쿠버네티스 API 버전이 어떤 것인지
#명시한다.
apiVersion: v1
#어떤 종류의 오브젝트를 생성하고자 하는지 명시한다.
kind: PersistentVolume
#이름 문자열, UID, 그리고 선택적인 네임스페이스를 포함하여
#오브젝트를 유일하게 구분지어 줄 데이터이다.
#서비스 이름(name)은 mysql-pv-volume.
#name은 동일한 namespace 상에서는 유일한 값을 이름으로 가져야 합니다.
#label은 특정 k8s object만을 나열한다거나 검색할 때 유용하게 쓰일 수 있는 key-value 쌍입니다.
metadata:
name: mysql-pv-volume
labels:
type: local
#오브젝트에 대해 어떤 상태를 의도하는지 명시한다.
spec:
#퍼시스턴트볼륨클레임의 스포리지클래스 이름을 manual로 정의하며,
#퍼시스턴트볼륨클레임의 요청을 이 퍼시스턴트볼륨에 바인딩하는데 사용한다.
storageClassName: manual
capacity:
#볼륨의 크기를 20기가바이트로 지정
storage: 20Gi
#ReadWriteOnce 접근 모드는 단일 노드가 읽기-쓰기 모드로 볼륨을 마운트할 있다는 뜻
accessModes:
- ReadWriteOnce
#사용자는 hostPath 퍼시스턴트볼륨을 생성한다. hostPath 퍼시스턴트볼륨은
#네트워크로 연결된 스토리지를 모방하기 위해, 노드의 파일이나 디렉터리를 사용한다.
hostPath:
path: "/mnt/data"
---
#여기서는 퍼시스턴트볼륨클레임을 생성한다. 이를 사용하여 물리적인 스토리지를 요청한다.
#여기서는 사용자는 적어도 하나 이상의 노드에 대해 읽기-쓰기 접근을 지원하며
#최소 20기가를 요청하는 퍼시스턴트볼륨클레임을 생성한다.
apiVersion: v1
#어떤 종류의 오브젝트를 생성하고자 하는지 명시한다.
kind: PersistentVolumeClaim
#이름 문자열, UID, 그리고 선택적인 네임스페이스를 포함하여
#오브젝트를 유일하게 구분지어 줄 데이터이다.
#서비스 이름(name)은 mysql-pv-claim이다.
metadata:
name: mysql-pv-claim
spec:
#위에서 PV를 설정할 때 storageClassName: manual랑 바인딩함.
#퍼시스턴트볼륨클레임의 요청을 이 퍼시스턴트볼륨에 바인딩하는데 사용한다. 즉
#이걸로 PV를 바인딩함.
storageClassName: manual
#여기서는 사용자는 적어도 하나 이상의 노드에 대해 읽기-쓰기 접근을 지원함
accessModes:
- ReadWriteOnce
resources:
requests:
#최소 20기가 요청
storage: 20Gi
- YAML 파일의 PV와 PVC를 배포한다.
kubectl apply -f https://k8s.io/examples/application/mysql/mysql-pv.yaml
- YAML 파일의 다른 오브젝트들을 배포한다.
kubectl apply -f https://k8s.io/examples/application/mysql/mysql-deployment.yaml
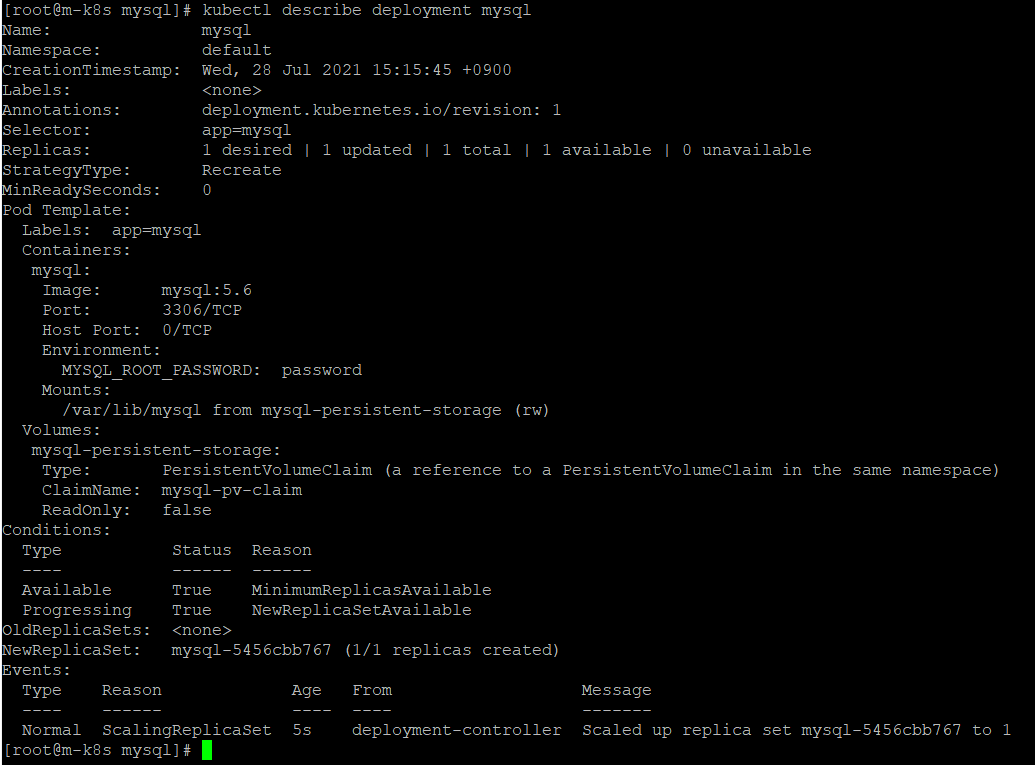
- 디플로이먼트에 관한 정보를 확인한다.
kubectl describe deployment mysql
MySQL 인스턴스 접근하기
이전의 YAML 파일은 클러스터의 다른 파드가 데이터베이스에 접근할 수 있는 서비스를 생성한다. clusterIP: None 서비스 옵션을 사용하면 서비스의 DNS 이름을 직접 파드의 IP 주소로 해석하도록 처리한다. 이 방법은 서비스에서 연결되는 파드가 오직 하나 뿐이고, 파드의 수를 더 늘릴 필요가 없는 경우에 가장 적합하다.
서버에 접속하기 위하여 MySQL 클라이언트를 실행한다.
kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -ppassword
이 명령어는 MySQL 클라이언트를 실행하는 파드를 클러스터에 생성하고, 서비스를 통하여 서버에 연결한다. 연결된다면, 스테이트풀 MySQL 데이터베이스가 실행 중임을 알 수 있다.
위 코드를 간단하게 해석해 보자. 자세한 내용은 명령어 kubectl run –help를 통해 알 수 있다.
kubectl run NAME –image=image는 클러스터에서 지정된 이미지를 실행하는 명령이다.
-it의 i 옵션은 stdin(standard input, 표준 입력)이고, t는 tty(teletypewriter)를 뜻한다. 이 두개를 합친 it는 표준 입력을 명령줄 인터페이스로 작성한다는 의미이다. 즉 쉘로 접속하여 컨테이너 상태를 확인하는 경우에 사용한다.
-p는 -p는 mysql를 접속하기 위한 password이다. 즉 우리가 설정했던 비밀번호는 ‘password’이기 때문에 ‘password’를 입력한다.
–restart=NEVER 컨테이너가 종료된 이유에 관계없이 컨테이너가 다시 시작되지 않는다.
–rm은 true인 경우 연결된 컨테이너에 대해 이 명령에서 생성된 리소스를 삭제한다.
-h는 mysql hostname를 의미한다. 즉 여기서 호스트네임은 mysql이다.

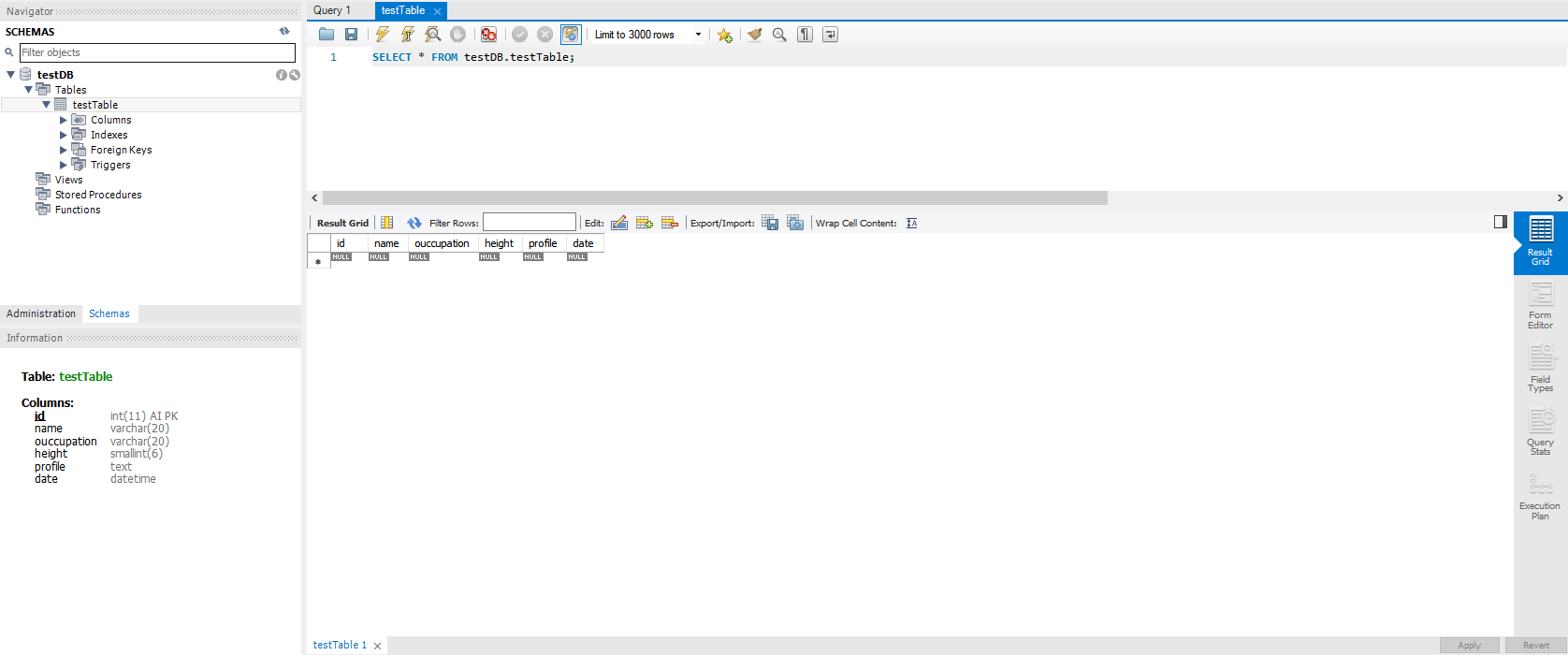
workbench에서 테스트할 수 있게 간단하게 데이터베이스와 테이블을 구성한다.
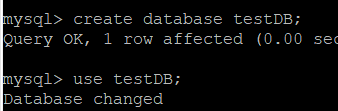
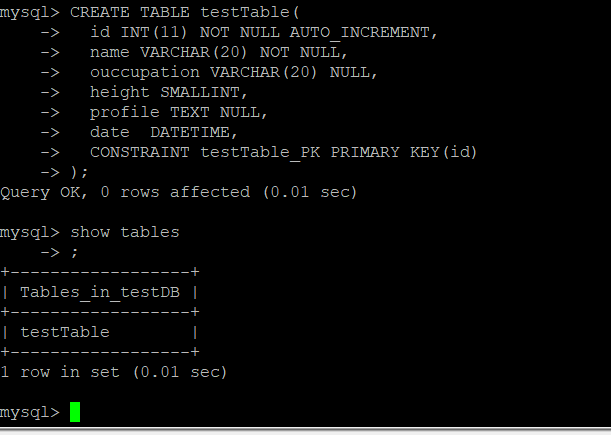
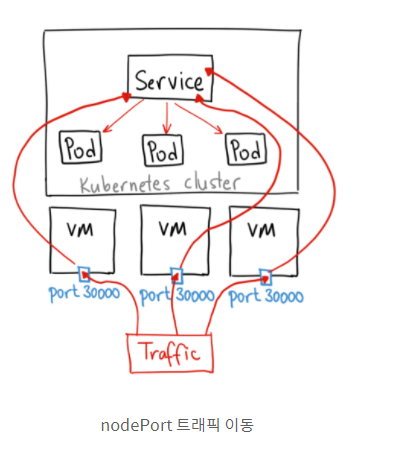
이제 테이블이 만들어졌다. 외부에서 클러스터의 내부에 접속하는 가장 쉬운 방법은 노드포트(NodePort) 서비스를 이용하는 것이다. 노드포트 서비스를 설정하면 모든 워커 노드의 특정 포트(노드포트)를 열고 여기로 오는 모든 요청을 노드포트 서비스로 전달한다. 그리고 노드포트 서비스는 해당 업무를 처리할 수 있는 파드로 요청을 전달한다.
노드포트를 설정할 yaml 파일을 살펴보자.
nodeport.yaml
apiVersion: v1
kind: Service
metadata:
#서비스 이름
name: mysql-nodeport
spec:
ports:
#기본적으로 그리고 편의상 'targetPort'는
#'port' 필드와 동일한 값으로 설정된다.
#즉 nodePort로 설정한 30003포트로 요청이 들어오면
#3306포트로 연결시켜준다는 것이다.
- port: 3306
#내부에 있는 컨테이너를 연결해주기 위하여 3306포트를 사용하는 것이다.
targetPort: 3306
#고정 포트(NodePort)로 각 노드의 IP에 서비스를 노출시킨다.
#NodePort 서비스가 라우팅되는 ClusterIP 서비스가 자동으로 생성된다.
#<NodeIP>:<NodePort>를 요청하여, 클러스터 외부에서 NodePort 서비스에 접속할 수 있다.
#즉 워커노드의 특정 포트를 열고(nodePort) 여기로 오는
#모든 요청을 노드포트 서비스로 전달하고 노드포트 서비스는
#해당 업무를 처리할 수 잇는 파드로 요청을 전달한다.
#노드에 오픈할 Port를 지정하는 것이다(미지정시 30000-32768 중에 자동 할당된다.)
#외부에 노드포트로 expose하기 위해 30000번 포트를 지정한다.
#이것은 expose 명령으로도 대체가 가능하나 이 30000번은 쓸 수 없다.
nodePort: 30000
selector:
app: mysql
#서비스 타입을 설정
type: NodePort
이제 이 파일을 현재 디렉터리에서 만든다음 실행한다.
kubectl create -f nodeport.yaml
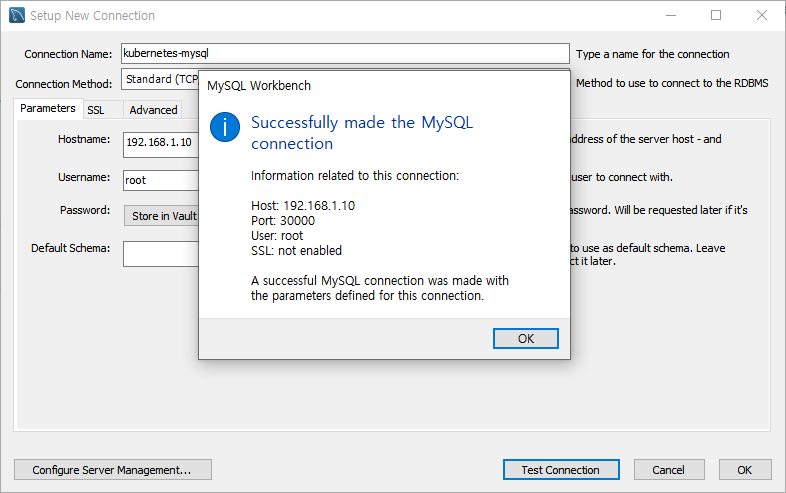
마지막 설정만 남았다. workbench로 접속하고 새로운 컨낵션을 설정해본다.
그전에 아이피를 확인한다.
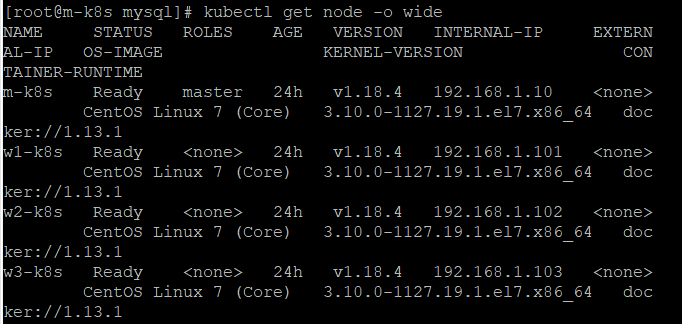
현재 마스터노트 1개와 워커노드3개가 있는데 마스터 노드의 아이피를 확인한다. 192.168.1.10 인 것을 확인할 수 있다. 이것을 복사한다.
workbench 설정은 아래 사진과 같이 한다.
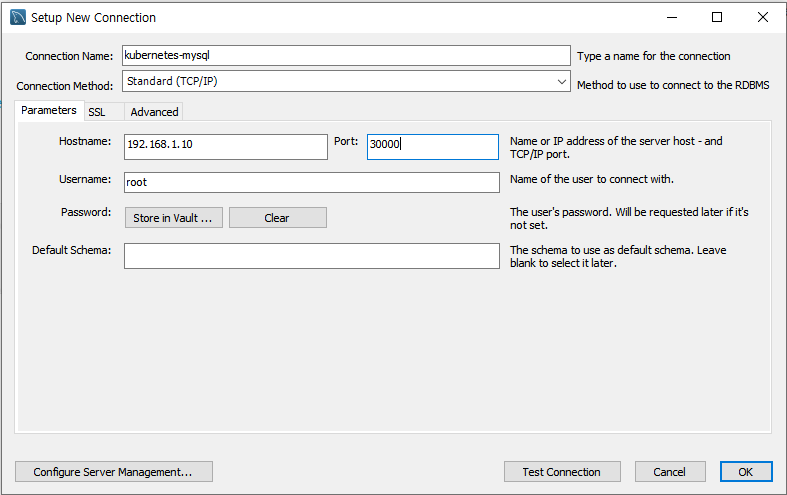
그리고 Test Connection를 누르면 성공하는 것을 볼 수 있다.
해당 컨넥션을 접속하면 아래 사진과 같이 우리가 만든 database와 table이 존재하는 것을 볼 수 있다.