해당 내용은 책 <컨테이너 인프라 환경 구축을 위한 쿠버네티스/도커>에 나오는 내용이며 이는 개인적으로 공부하기 위해서 게시하는 글임을 알립니다.
커피 중독자되는 중…
PV와 PVC
이번 포스팅에서는 컨테이너 인프라 환경 구축을 위한 쿠버네티스/도커 책의 저자가 만든 Kubernetes All-in-One Cluster Monitoring KR을 하나하나 분석해 보려 한다. 나중에 내가 써야할 일이 있을 수도 있고 분석함으로써 나중에 내가 내것을 직접 만드는데 많은 도움이 될 것 같아서다.
Kubernetes All-in-One Cluster Monitoring
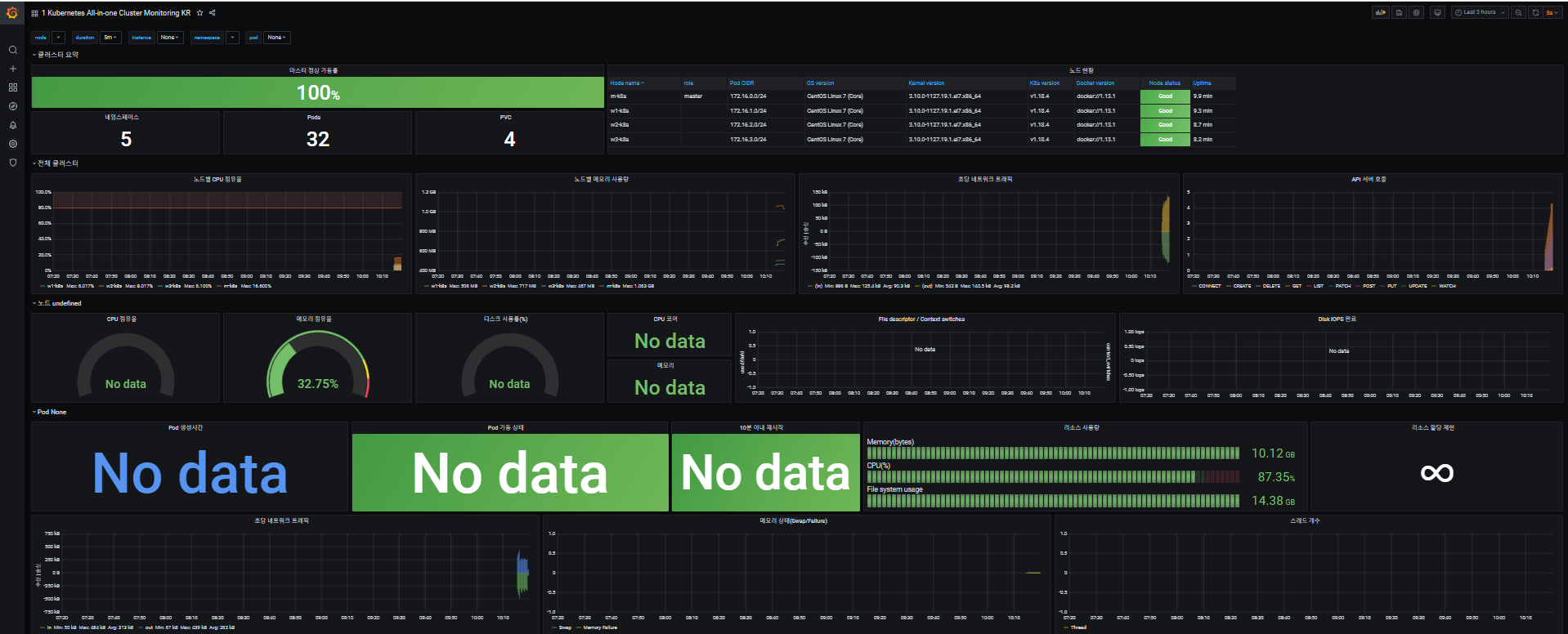
위 사진에서 나오는 대시보드를 차례대로 봐보자.

위 대시보드와 관련한 기본정보는 아래 사진과 같다.
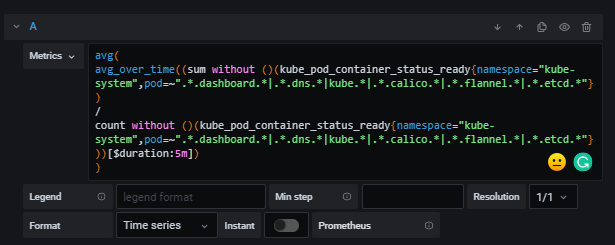
아마 메트릭 구성(PromQL)을 분석하는 것이 제일 어려울 듯 싶다. 하지만 천천히 하나하나 알아가 보자.
메트릭은 PromQL(Prometheus Query Language)으로 구성되어 있다.
avg(
avg_over_time((sum without ()(kube_pod_container_status_ready{namespace="kube-system",pod=~".*.dashboard.*|.*.dns.*|kube.*|.*.calico.*|.*.flannel.*|.*.etcd.*"})
/
count without ()(kube_pod_container_status_ready{namespace="kube-system",pod=~".*.dashboard.*|.*.dns.*|kube.*|.*.calico.*|.*.flannel.*|.*.etcd.*"}))[$duration:5m])
)
- avg(): 평균값을 반환한다.
- avg_over_time(): 지정된 간격에 있는 모든 포인트의 평균 값을 반환한다.
- sum: 합계를 반환
- without: by도 있는데 without과 group by와 같은 역할을 한다. without은 by의 반대 관계이다. 즉 without을 사용하면 해당 label은 제외하고 나머지로 group by를 한다.
예를 들어 process_count에 group이라는 라벨이 있다고 할 경우 아래와 같이 사용할 수 있다.
sum (process_count_total) without (group)
이런 식으로 사용할 수 있다. 여기서 주의해야 할 점은 by 또는 without 다음에 오는 label list는 괄호로 묶여야 하다는 점이다. 괄호로 묶지 않으면 정상적인 쿼리문이 아니게 된다. 추가로 vector expression이 길다면 by 또는 without 구문을 앞으로 가져올 수 있다.
sum by (group) (process_count_total)
여기서는 이 형식을 사용했다.
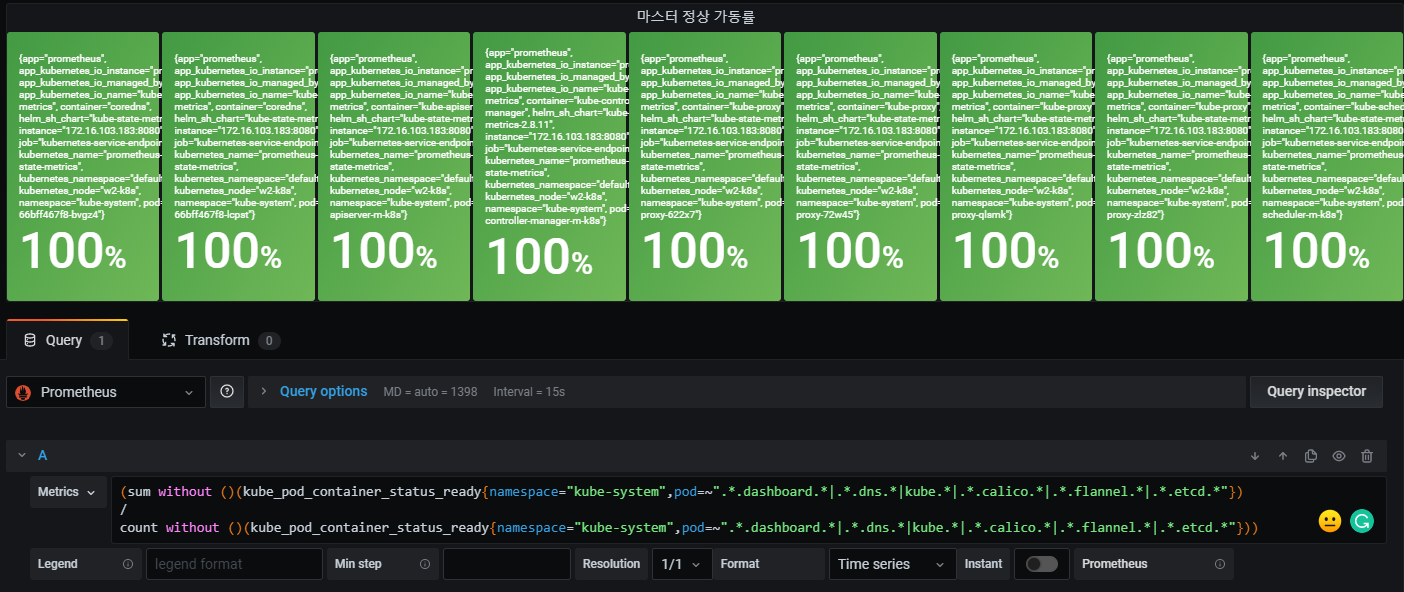
- kube_pod_container_status_ready: 컨테이너의 준비 확인이 성공했는지 여부를 설명한다.(퍼센티지로 표시)
- namespace=”kube-system”: 현재 내 클러스터 내에 네임스페이스 중 “kube-system”를 의미한다.
superputty에서
kubectl get namespace
를 입력하면 "kube-system"이 있는 것을 볼 수 있다. - =~: 정규식 표현을 이용할 수 있는 operator이다.
.: 임의의 문자 [단 '`는 넣을 수 없다.]
|: 패턴을 OR 연산을 수행할 때 사용한다.
즉 여기서는 클러스터내 kube-system 네임스페이스에 있는 파드 중에 dashboard, dns, kube, calico, flannel, etcd라는 문자열이 들어가 있는 파드를 모두 선택하는 것이다.
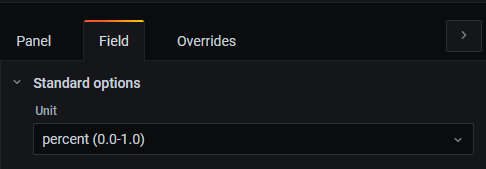
- [$duration: 5m]: $ 표시는 미리 등록한 변수를 사용하는 것이다. 대시보드의 setting에 들어가면 변수를 확인할 수 있다.
- /: 산술 연산자에서 나누기를 의미
다음 지표를 보자.
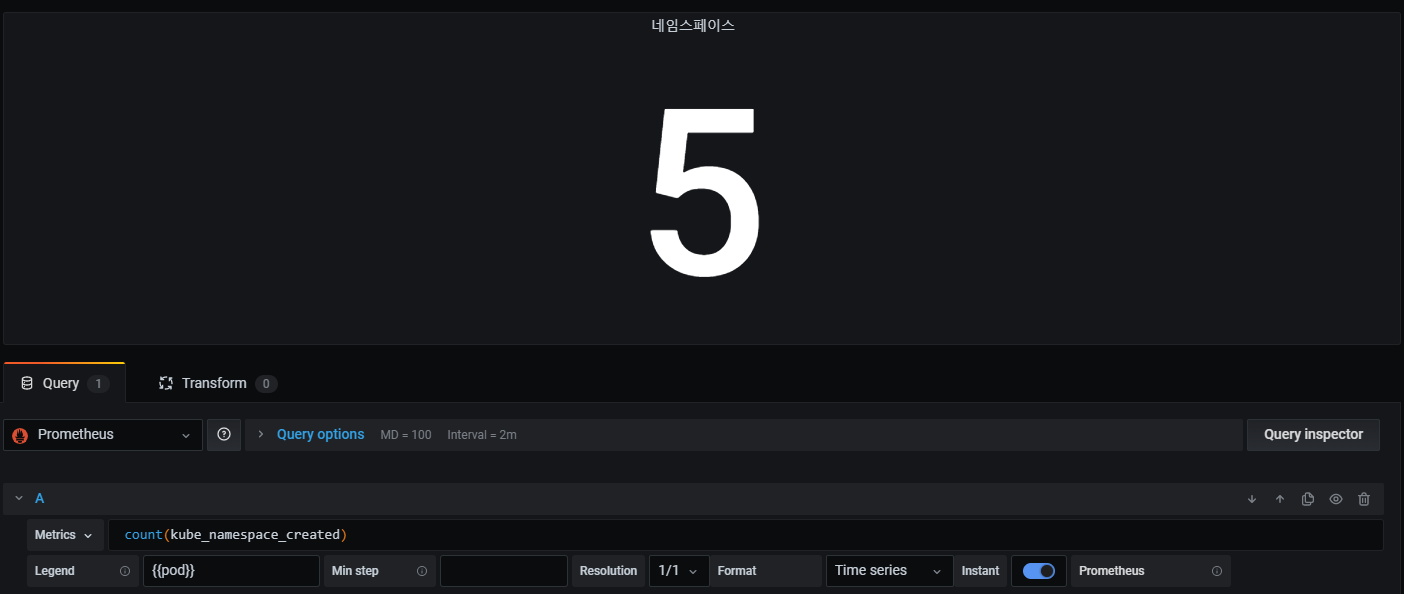
다음은 쉽다 그냥 클러스터내에 존재하는 namespace의 개수를 가져온다.
count(kube_namespace_created)
다음 지표는 클러스터 내에 존재하는 모든 pod의 수를 반환한다.
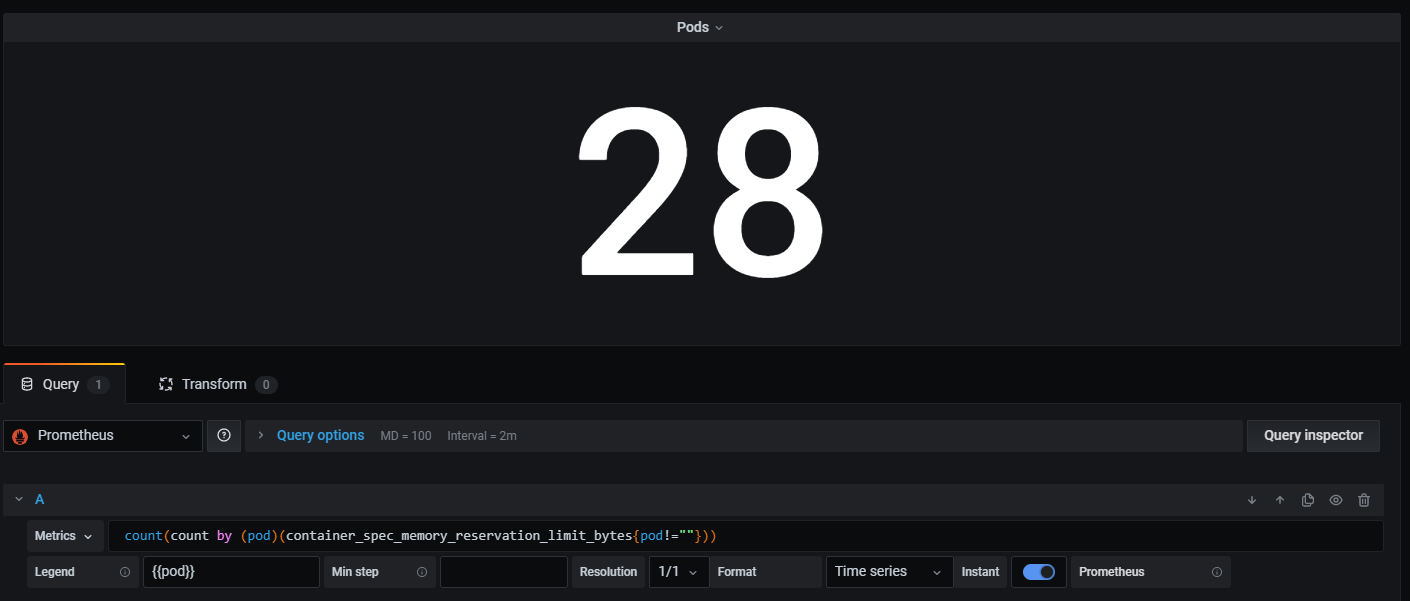
count(count by (pod)(container_spec_memory_reservation_limit_bytes{pod!=""}))
- container_spec_memory_reservation_limit_bytes: 컨테이너가 예약할 수 있는 메모리 한계를 표시한다.
- {pod!=””}:파드의 이름이 빈 문자열이 아닌 것을 다 조회한다. 즉 모든 파드를 조회한다는 것이다.
- count by (pod)(): 파드는 여러 개의 컨테이너를 가질 수 있다. 그래서 (pod), 즉 파드로 group by 하고 그것을 카운팅하는 것이다. 아래 사진을 참고한다.
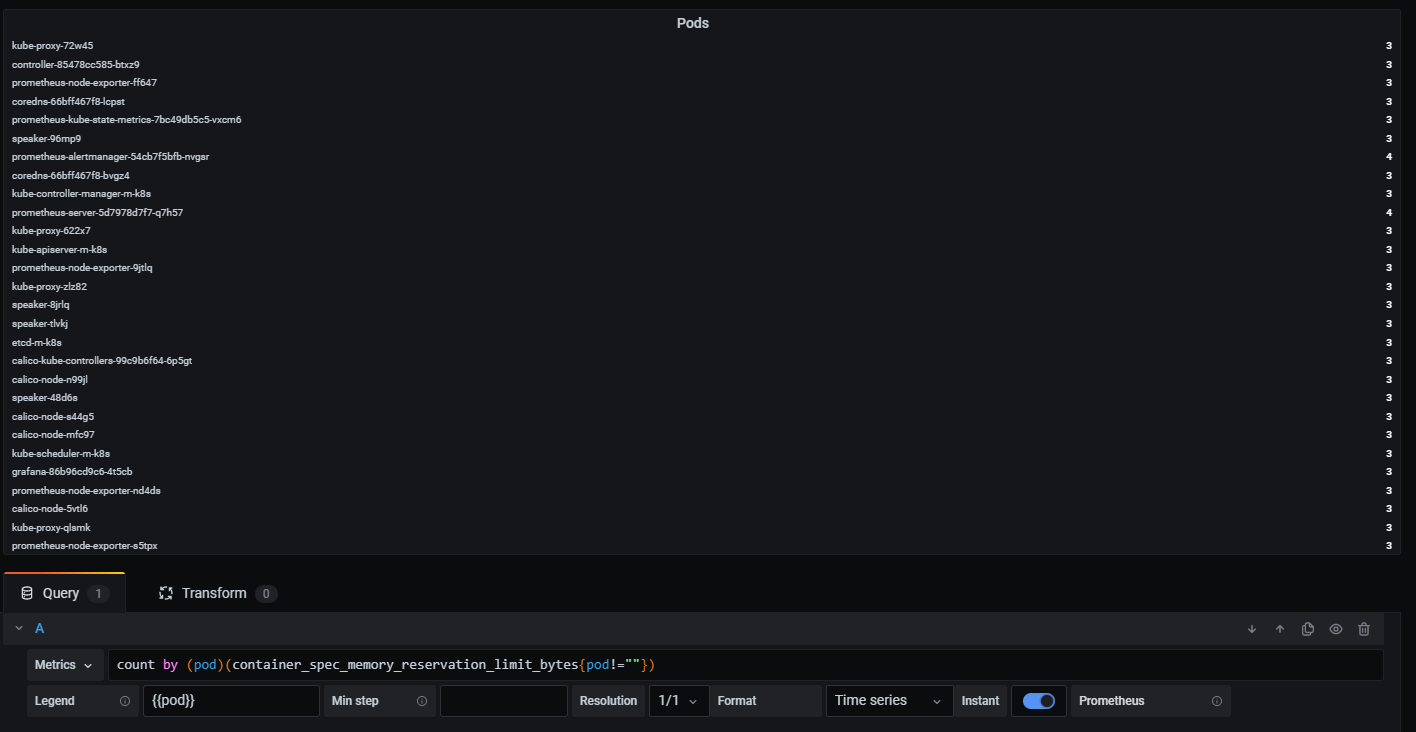
- count(): 위의 사진에 나오는 모든 파드들의 수를 구한다.
다음 지표는 아래와 같다.
PVC의 개수를 구하는 지표다.
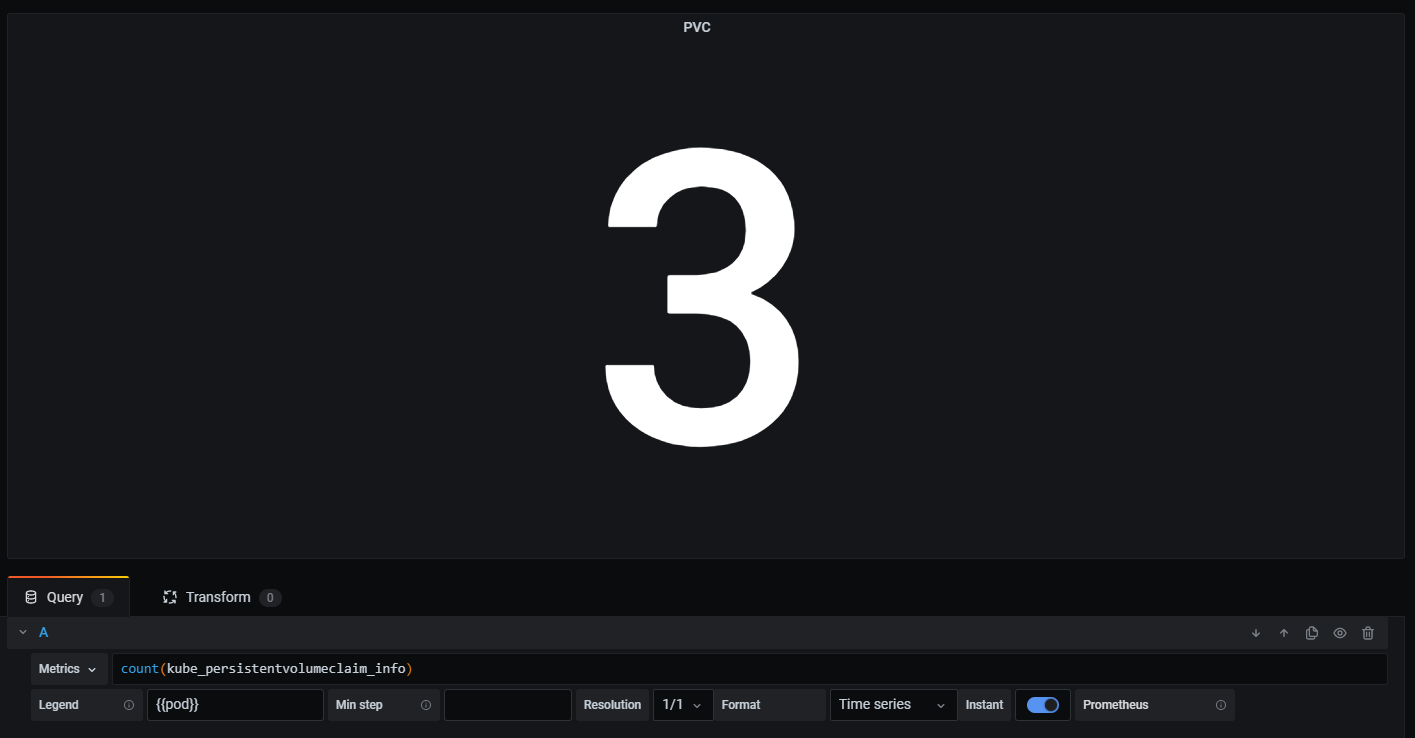
count(kube_persistentvolumeclaim_info)
- kube_persistentvolumeclaim_info: PV와 PVC의 매핑 정보를 반환하는데 여기서는 개수를 구하는 것임으로 count로 그 개수를 구한다.

이 대시보드에 구성은 테이블로 되어 있다. 컬럼 구성은 Transform에서 볼 수 있다. 아래 사진을 참고하자.
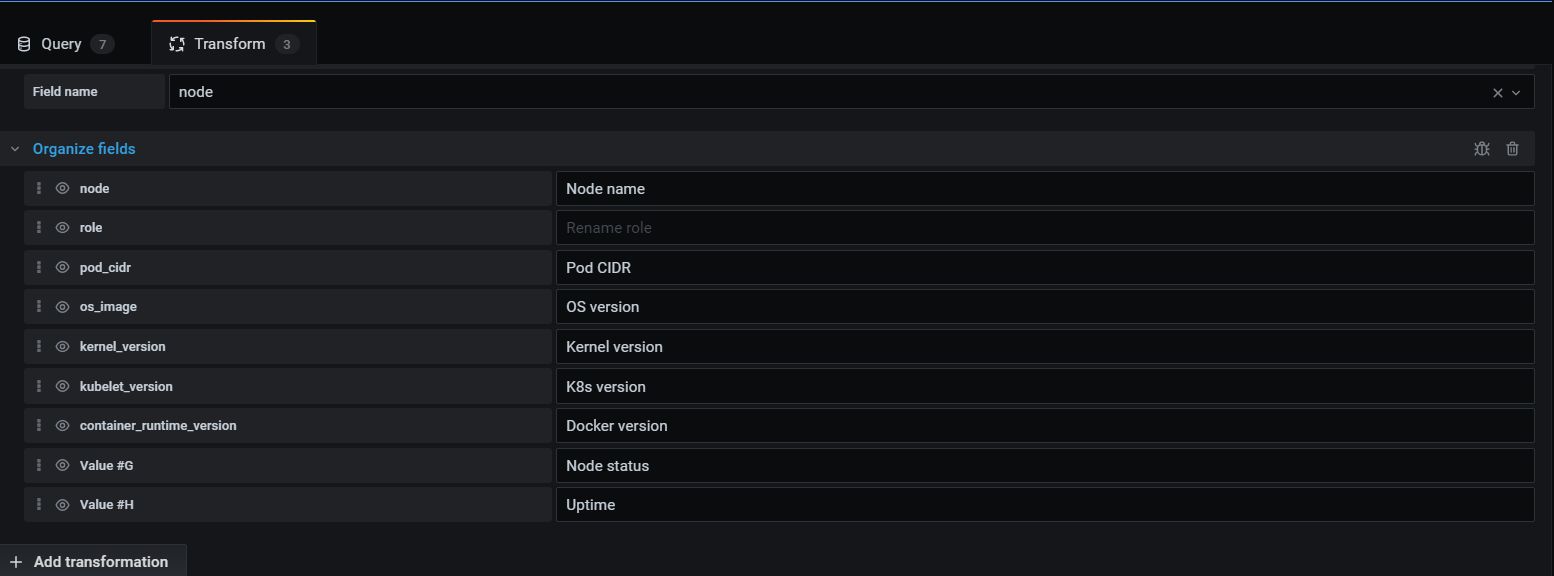
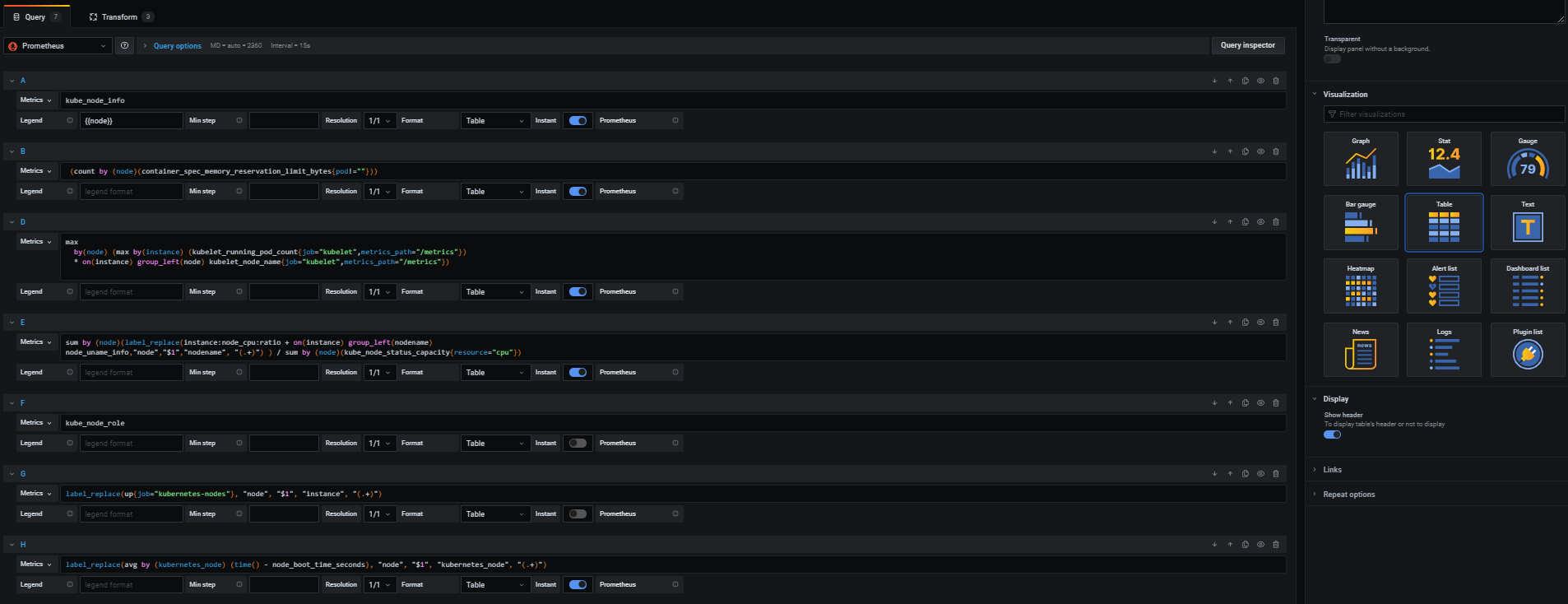
뭔가 많은 것을 볼 수 있는데 하나 하나 봐 보자.

kube_node_info
- kube_node_info: 클러스터 노드에 대한 정보를 반환한다.
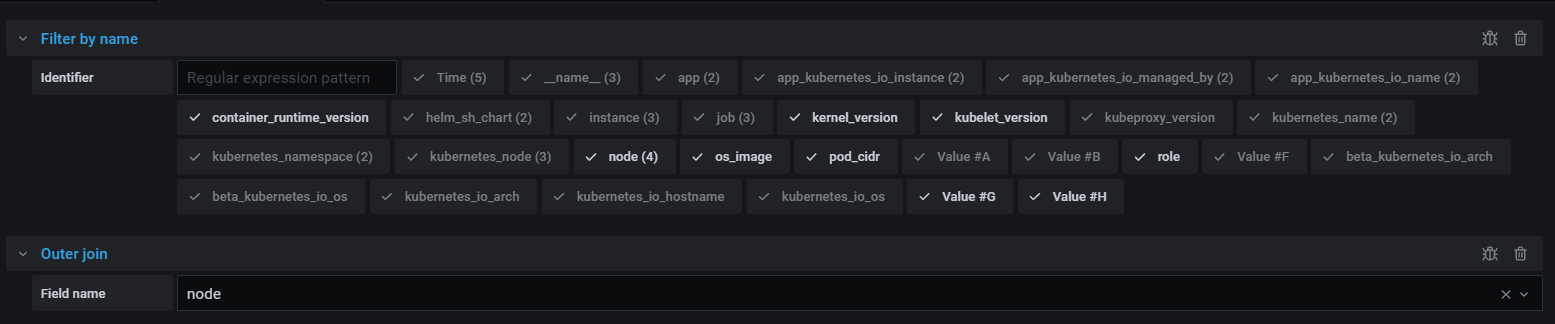
지금 Query가 A, B, D, E, F ,G, H 이렇게 있는데 B, D, E는 이 대시보드에서 표시되지 않는 내용이다. 프로메테우스로 값을 확인해보려고 돌려보니 값을 찾을 수가 없었다. 왜 추가한지는 잘 모르겠다. 그래서 나는 이 B, D, E 쿼리는 해석하지 않으려 한다. 바로 F를 보자.

kube_node_role
- kube_node_role: 클러스터 노드에 역할 정보를 반환한다.
Query G를 보자.

label_replace(up{job="kubernetes-nodes"}, "node", "$1", "instance", "(.+)")
- label_replace(v instant-vector, dst_label string, replacement string, src_label string, regex string): v안에 각 시계열에 대해 labe_replace는 레이블 src_label의 값에 대해 정규식 regex와 일치시킨다. 만약 일치한다면 시계열에서 리턴된 레이블 dst_label의 값은 입력의 원래 레이블들과 함께 확장이 된다. 정규식의 캡처 그룹은 $1, $2 등으로 참조할 수 있습니다. 정규식이 일치하지 않으면 시계열이 변경되지 않고 반환됩니다.
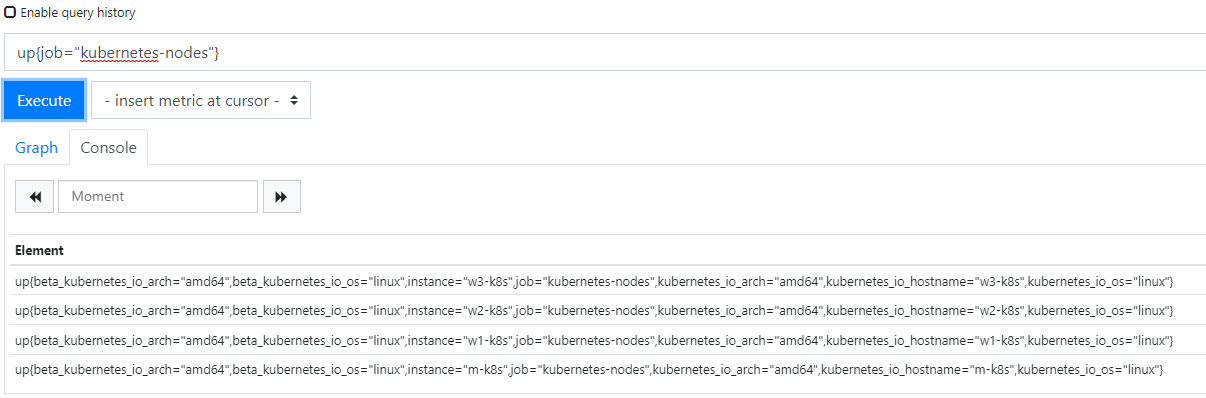
label_replace()를 추가하고 나면 위 사진에서 node 레이블과 값이 추가된 것을 볼 수 있다.(아래 사진 참고)
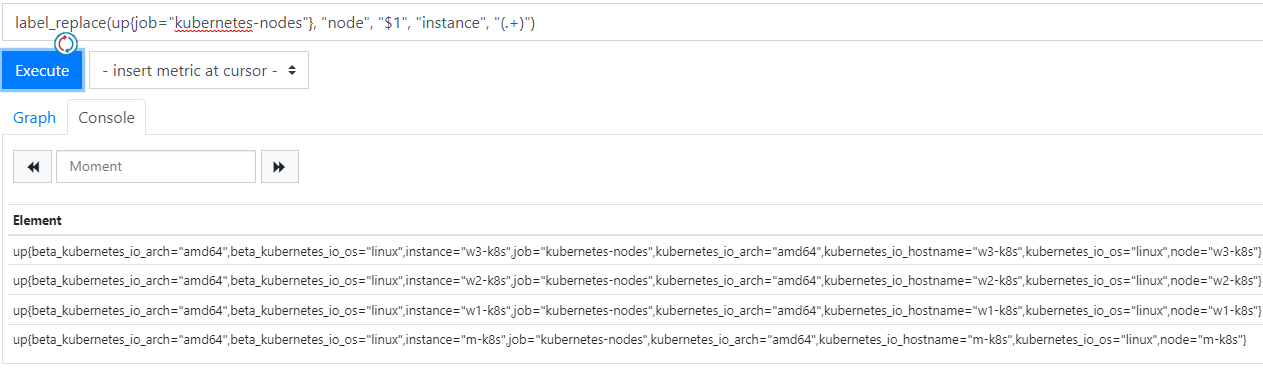
- up: up은 수집 대상이 작동하고 있는지 알려준다. 결과로 나온 메트릭 데이터를 보면 up이라는 메트릭 이름을 가지는 대상을 검색하고 그중에 job=”kubernetes-nodes”라는 레이블 이름을 검색 조건에 추가한다. 이를 일반적으로 필터링이라고 하고 검색 조거네 맞는 메트릭 데이터가 존재하고 추출에 성공하면 1이라는 값으로 표현한다. 즉 여기서 1의 값을 가지니까 Node Status 값이 Good를 표시한다.
다음 H Query를 보자.

label_replace(avg by (kubernetes_node) (time() - node_boot_time_seconds), "node", "$1", "kubernetes_node", "(.+)")
- time(): 1970년 1월 1일 UTC 이후 경과된 시간(초)을 반환한다. 이것은 실제로 현재 시간을 반환하는 것이 아니라 표현식이 평가되는 시간을 반환한다는 점에 유의해야 한다.
- node_boot_time_seconds: 노드의 부팅 시간(리눅스타임)
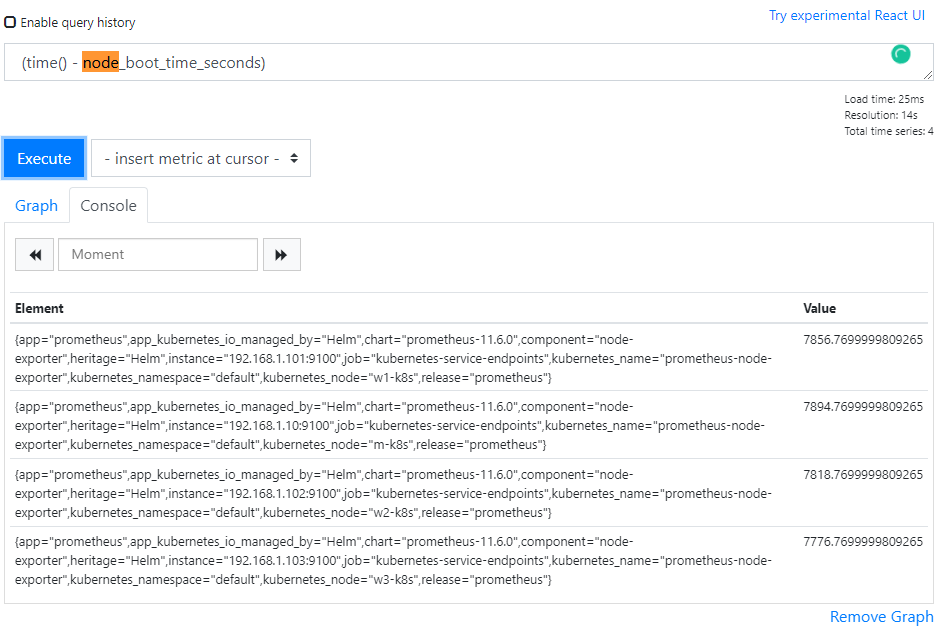
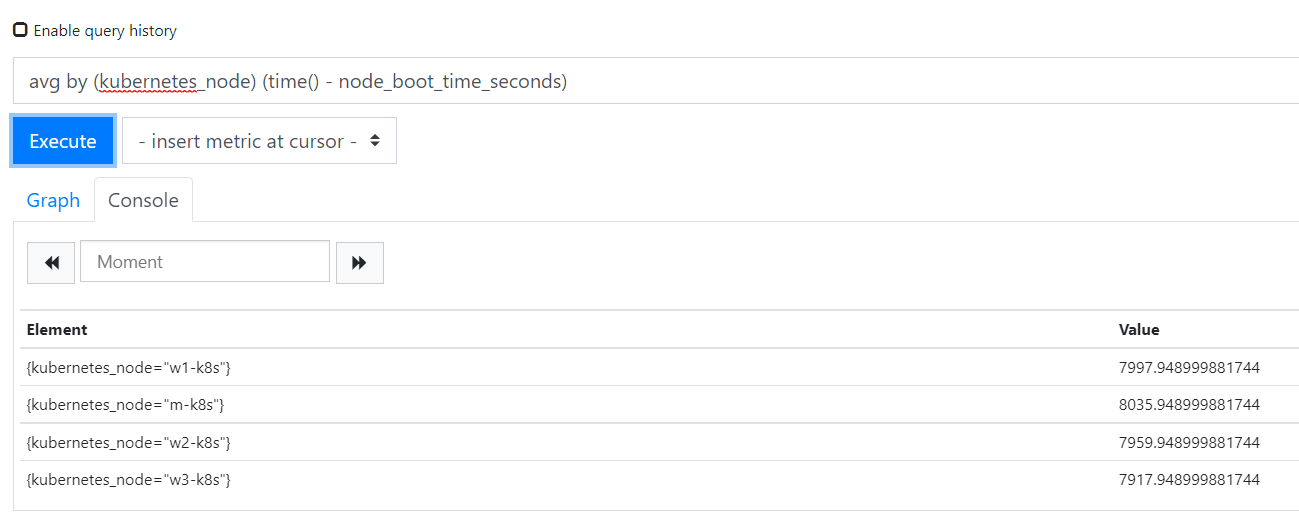
그리고 이 쿼리로 인해 대시보드의 Uptime이 표시되는 것을 볼 수 있다.
다음 대시보드다.
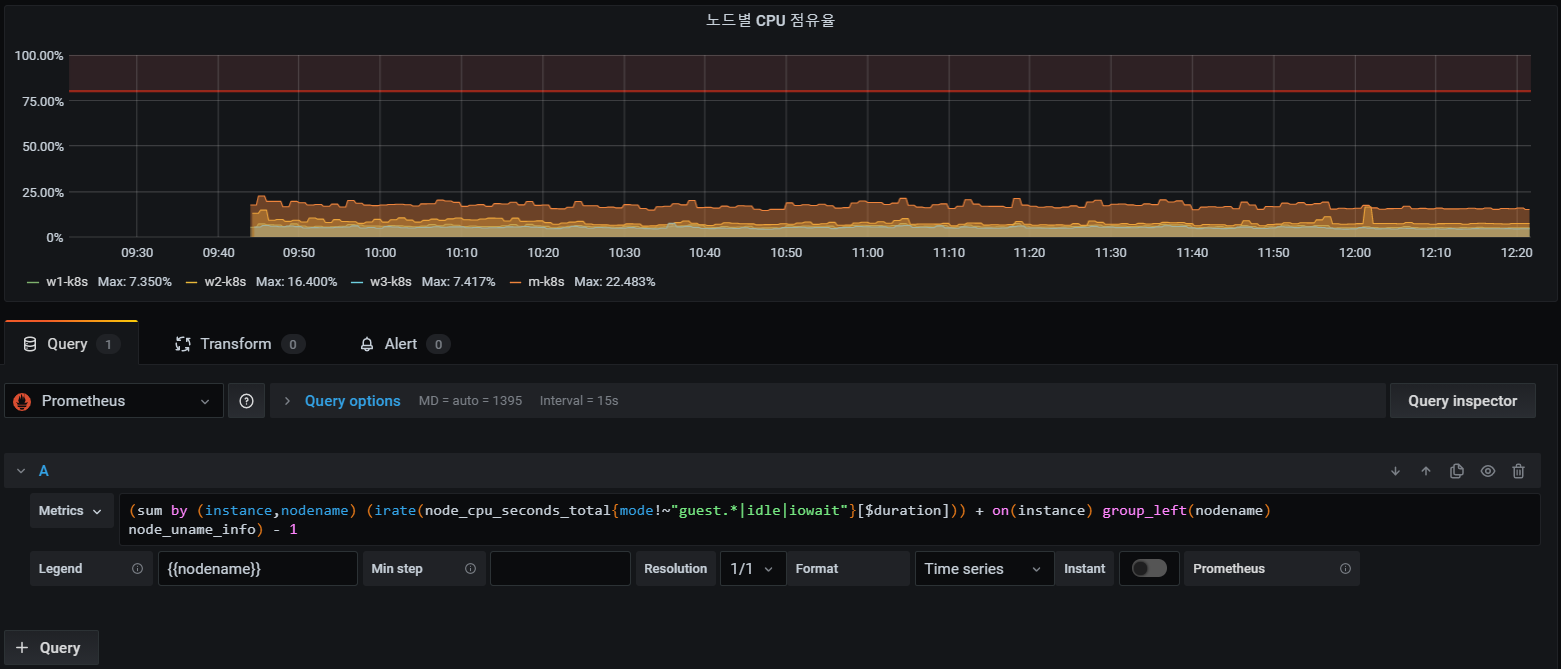
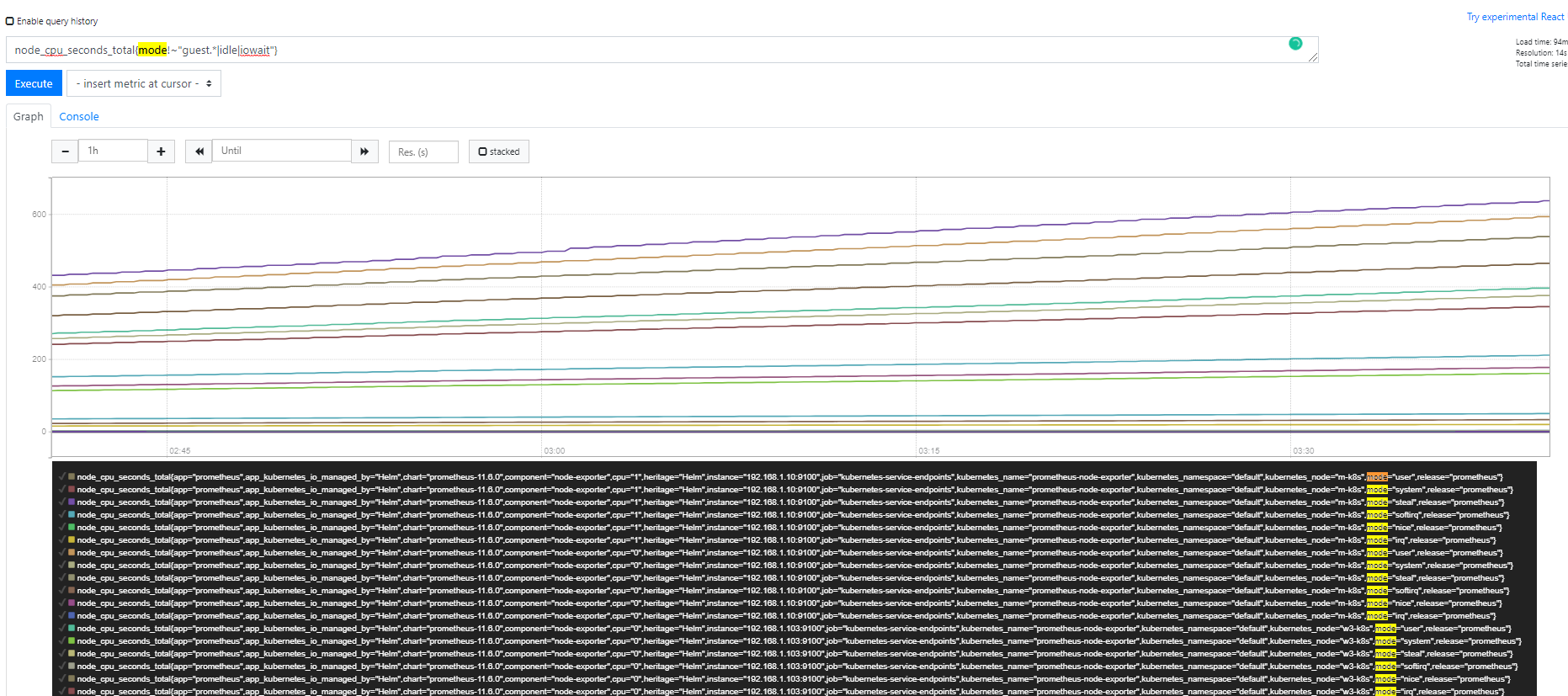
(sum by (instance,nodename) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}[$duration])) + on(instance) group_left(nodename)
node_uname_info) - 1
- node_cpu_seconds_total: 노드의 총 CPU 사용 시간을 파악할 수 있다.
- idle: CPU가 할 일이 없는 시간
- guest: vm를 돌리고 있다면 사용하고 있는 cpu를 의미
- rate(node_cpu_seconds_total{mode=”system”}[1m]): 지난 1분 동안 시스템 모드에서 사용한 평균 CPU 시간(초)
- irate(v range-vector): 범위 벡터에서 시계열의 초당 순간 증가율을 계산한다. 이것은 마지막 두 데이터 포인트를 기반으로 한다. rate는 구간 시작 값과 구간 종료 값의 차이에 대한 변화율을 다루고 irate는 구간 종료 바로 전 값과 구간 종료 값의 차이에 대한 변화율을 나타낸다는 점이 다르다. 따라서 구간이 매우 길면 irate의 변화율은 큰 의미가 없기 때문에 rate 함수를 사용하는 것이 낫다.
- !~: 조건에 넣은 정규 표현식에 해당하지 않는 메트릭을 보여준다. 예를 들어 {instance!~ “w.+”}는 instance 레이블 값이 w로 시작하지 않는 모든 메트릭을 찾아 출력한다.
- : 노드의 부팅 시간(리눅스타임)
