동전 0-11047
이번 문제도 비교적 쉬운 편이다. 문제는 아래와 같다.
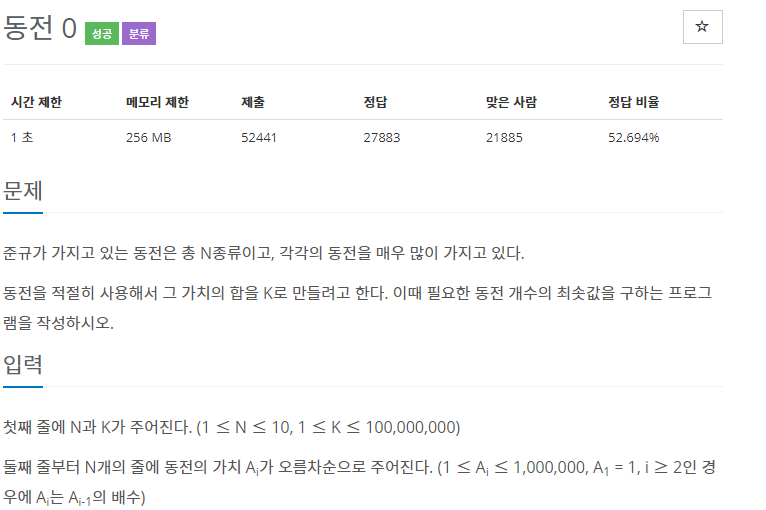
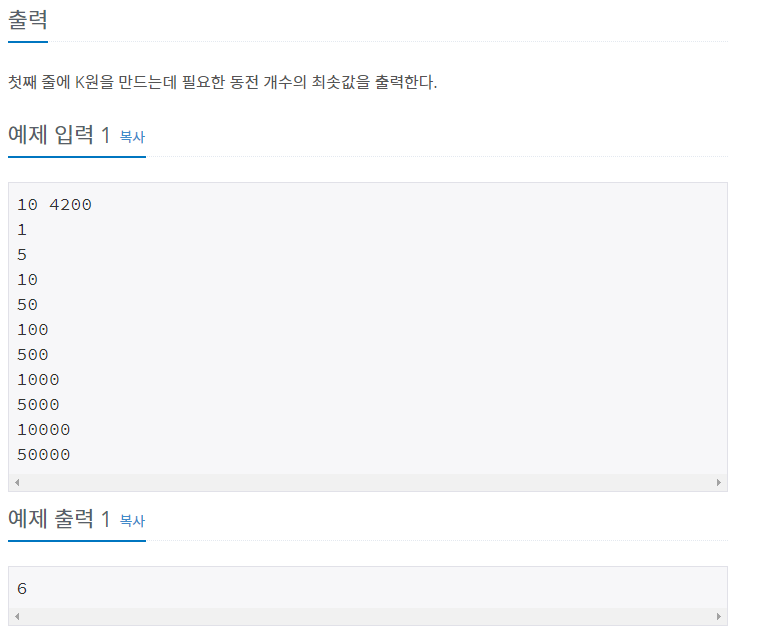
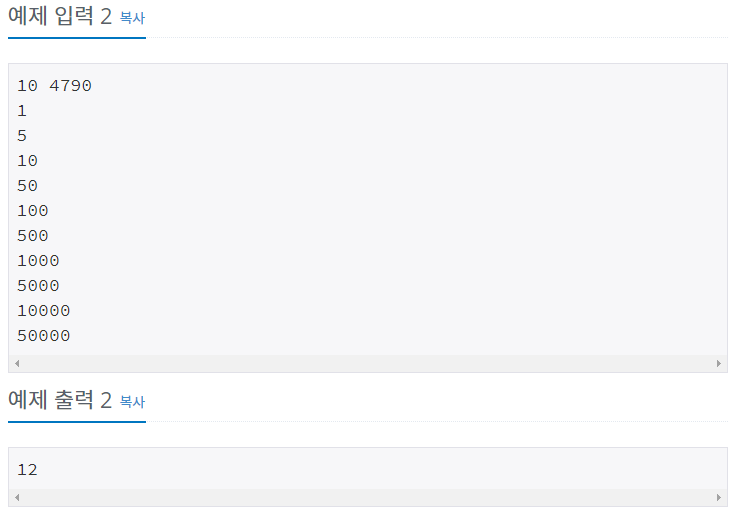
코드를 짜는 건 그리 어렵지 않았으나 문제가 하나 생겼다. 이전 C++로 이 같은 문제를 풀 때 같은 로직으로 파이썬으로 짰지만 시간 초과가 나버렸다.

이상하게 여겨서 혹시나 하고 채점할 때 PyPy3로 설정하고 돌려봤다. 그런데 신기하게도 답이 맞게 나왔다!!

PyPy3가 뭐길래 Python3와는 다르게 성공하는 걸까? 그 부분에 대해서는 Python Category에서 다루도록 하겠다. 일단 처음으로 내가 짠 코드를 보자
N,K=input().split()
N=int(N)
K=int(K)
l=[]
ans=0
for i in range(N):
l.append(int(input()))
cnt=len(l)
while(K):
if K<l[cnt-1]:
cnt-=1
else:
K-=l[cnt-1]
ans+=1
print(ans)
일단 입력 부분에 대한 설명은 생략하고 while문 안을 봐보자. cnt를 인덱스로 삼아서 정렬되어 있는 데이터에서 가장 끝부분부터 K와 비교해서 K보다 작으면 그만큼을 빼준다. 그리고 다시 while문을 돌게 되는데 이때는 비효율적인 것을 알지 못했다. 가령 K가 5000이고 l[cnt-1]가 1000이라고할 때 while문은 총 5번을 돌것이다. 그럼 아래 코드를 봐보자.
N,K=map(int, input().split())
l=[]
ans=0
for i in range(N):
l.append(int(input()))
while(K):
coin=l.pop()
ans+=K//coin
K%=coin
print(ans)
이 코드의 입력은 똑같고 while문 안을 보면 조금 다르다. 여기서는 빼는 대신 나눠주고 있는 모습을 볼 수 있다. 즉 아까의 예에서 K가 5000이고 l[cnt-1]가 1000이라면 한 번만에 답을 찾아내는 것이다. 왜 시간초과가 났는지 알 수 있는 대목이다….
이 바보..
끝에서부터 데이터를 pop 해서 coin에 넣은다음에 그것을 K로 나눠준다. 이때 K보다 coin이 크다면 ans에 0를 더해주게 될 것이다.그래서 0이 안되는 순간 나눠주고 몫을 ans에 누적시켜서 출력하면 되는 것이다. 이게 가능한 이유는 데이터가 오름차순으로 정렬되어 있기 때문이다. 끝에서부터 pop 시켜서 나눠준다면 제일 큰 데이터에서부터 작은 데이터까지 pop 되면서 데이터 크기가 내려갈 것이다.
단순하지만 많은 배울 점을 준다. 만약 K가 100000 였고 coin이 10이였다면 내 코드는 10000번 while문을 돈다면 두 번째 코드는 1번만 돌 것이다.
그래서 시간초과가 났던 것이다. 이런 비효율적인 문제 때문에 오래걸렸던 것이다. 앞으로는 생각을 좀 더 해볼 필요가 있을 것 같다.
