3달만에 블로그 포스팅…
Backend Interview Questions 모음-1
글을 너무 오랜만에 쓴다. 그동안 이것저것하느라 바쁘기도 했고 아무래도 취업을 준비해야 하다보니 정신이 없었다. 내가 벌써 4학년이라는 게 믿기지가 않는다. 생각보다 오랜 시간이 지난거 같은데 이 포스트를 작성하기 전 마지막 포스트가 2021년 8월 29일인 것을 보면 그다지 많이 지난 것 같지 않다. 그동안 많은 실패 및 성공?(실패 90%, 성공 1%, 기타9%..) 이 있었다. 되돌아보면 가슴만 아프니까 여기까지만 하자. 이제 다시 마음 잡고 일어날 때다. 항상 힘들때면 되돌아보는 대사가 하나 있다. 그래도 이전에는 여유가 생기면 PC방에 가서 오버워치를 하는 즐거움도 있었는데 이제는 그러지도 못할 것 같다. 오버워치에 나오는 캐릭터 중에서 솔져76이 게임 도중에 하는 대사가 있다.

“쓰러뜨려 봐라. 다시 일어날테니”
오글거릴 수도 있는 나름 간단하면서 임펙트 있어서 좋아한다.
이제 헛소리 그만하고 본론을 써야겠다. 다시 블로그 글을 쓰게 된 이유는 면접 및 CS 지식을 다지기 위해서다. 오늘부터 차근차근 하나하나 자세하게 보며 써내려 가려고 한다. 하면서 많이 힘들겠지만 천천히 가는 만큼 더 많은 것을 볼 수 있지 않을까 싶다.
이번 편에서는 그동안 당근에서 면접을 봤던 사람들의 후기를 바탕으로 작성해보려 한다. 먼저 면접을 보신 선배님들이 겪으신 문제를 하나하나 보며 그것에 대해 답을 찾아나가려 한다.
“ElasticSearch의 키워드 검색과 RDBMS에서 %LIKE% 검색의 차이점”
관계형 데이터베이스에서 조건에 맞는 데이터를 검색할 때 주로 SQL를 사용한다.
SQL의 경우 정확히 일치하는 데이터를 검색하고 싶다면 where =’…‘를 이용할 수 있고 해당하는 단어가 포함된 데이터를 검색하고 싶다면 where like ‘%…%’와 같은 형식으로 훌륭하게 데이터 검색이 가능하다.
Elastic Search와 차이가 뭘까?
 관계형 데이터베이스와 일라스틱서치의 차이
관계형 데이터베이스와 일라스틱서치의 차이
- 관계형 데이터베이스는 단순 텍스트 매칭에 대한 검색만을 제공함
- MySql 최신 버전에서 n-gram 기반의 Full-text 검색을 지원하지만, 한글 검색의 경우에 아직 많이 빈약한 감이 있음
- 텍스트를 여러 단어로 변형하거나 텍스트의 특질을 이용한 동의어나 유의어를 활용한 검색이 가능
-
Elastic Search에서는 관계형 데이터베이스에서 불가능한 비정형 데이터의 색인과 검색이 가능
- 이러한 특성은 빅데이터 처리에서 매우 중요하게 생각됨
-
Elastic Search에서는 형태소 분석을 통한 자연어 처리가 가능
- Elastic Search는 다양한 형태소 분석 플러그인을 제공
- 역색인 지원으로 매우 빠른 검색이 가능
RESTful API를 사용하는 Elastic Search
관계형 DB와 Elastic Search를 비교했을 때 가장 커다란 부분 중 하나는 데이터의 CRUD를 하는 방식이 조금 다른 것이다.
관계형 DB의 경우 우리가 주로 데이터의 추가, 삭제 등을 위해 사용하는 방법은 클라이언트에서 관계형 DB가 있는 서버에 연결을 맺어 SQL을 날리는 방식이었을 것이다.
이를 테면 JDBC에서 관계형 DB가 있는 아이피와 포트를 연결하여 SELECT, INSERT, DELETE등의 쿼리를 날리는 방식이었다.
Elastic Search의 경우에는 이와 약간 다르다. 데이터를 CRUD하기 위해서 RESTful API라는 방식을 이용한다.
HTTP 통신에서 갖는 GET, POST, PUT, DELETE 등의 메서드가 RESTful API의 형식대로 그대로 적용된다. HEAD 메소드는 친숙하진 않지만, 특정 문서의 정보 유무를 확인하는데 이용될 수 있다.
또한 Elastic Search의 POST 즉, 데이터 삽입의 경우에는 관계형 데이터베이스와 약간 다른 특성을 갖고 있는데 스키마가 미리 정의되어 있지 않더라도, 자동으로 필드를 생성하고 저장한다는 점이다.
이러한 특성은 큰 유연성을 제공하지만 선호되는 방법은 아니다.
Elastic Search의 장점
데이터베이스 대용으로 사용가능
NoSQL 데이터베이스처럼 사용이 가능하다. 또한 분류가 가능하고 분산 처리를 통해 거의 실시간(NRT-Near Real Time)에 데이터 검색이 가능하다.
대량의 비정형 데이터 보관 및 검색 가능
기존 데이터베이스로 처리하기 어려운 대량의 비정형 데이터 검색이 가능하며, 전문 검색(Full-Text-Search)과 구조 검색 모두를 지원한다. 기본적으로 검색엔진이지만 MongoDB나 Hbase처럼 대용량 스토리지로 사용도 가능하다.
일라스틱 서치의 전문검색
정형 데이터, 비정형 데이터, 반정형 데이터
오픈소스 검색엔진
아파치 루씬(Lucene)기반 오픈소스 검색엔진으로 무료로 사용 가능하며, 많은 컨트리뷰터들이 실시간으로 소스를 수정해주기 때문에 버그가 발생하면 빠르게 해결된다.
전문 검색(Full-text Search)
내용 전체를 색인하여 특정 단어가 포함된 문서를 검색하는 것이 가능하다.
통계 분석
비정형 로그 데이터를 수집하고 한 곳에 모아서 통계 분석이 가능하다. 키바나를 이용하면 시각화 또한 가능하다.
스키마리스(Schemaless)
기존의 관계형 데이터베이스는 스키마라는 구조에 따라 데이터를 적합한 형태로 변경하여 저장 관리하지만 Elastic Search는 비정형의 다양한 형태의 문서도 자동으로 색인, 검색이 가능하다.
데이터베이스의 구조와 제약 조건에 관해 전반적인 명세를 기술한 것
RESTful API
RESTful API를 사용하여 HTTP 통신 기반으로 요청을 받아 JSON 형식으로 응답한다는 것은 다양한 플랫폼에서 응용 가능하다는 것을 의미한다.
멀티 테넌시(Multi-tenancy)
Elastic Search에서 인덱스는 관계형 DB의 데이터베이스와 같은 개념임에도 불구하고 서로 다른 인덱스에서도 검색할 필드명만 같으면 여러 개의 인덱스를 한번에 조회할 수 있다.
Document-Oriented
여러 계층의 데이터를 JSON 형식의 구조화된 문서로 인덱스에 저장 가능하다. 계층 구조로 문서도 한 번의 쿼리로 쉽게 조회 가능하다.
역색인(Inverted-Index)
역색인을 지원한다.
확장성과 가용성
매우 많은 데이터가 존재할 때 분산 시스템 구성으로 병렬적인 처리가 가능하다. 분산 환경에서는 데이터가 샤드(Shard)라는 단위로 나누어 제공된다. 인덱스 생성 시마다 샤드의 수 조정이 가능하다. 데이터의 종류와 성격에 따라 데이터를 분산하여 빠르게 처리 가능하다.
단점
‘실시간’(Real Time) 처리는 불가능
Elastic Search의 데이터 색인의 특징 때문에 Elastic Search의 색인된 데이터는 1초 뒤에나 검색이 가능하다. 왜냐하면 색인된 데이터가 내부적으로 커밋(Commit)과 플러시(Flush)와 같은 과정을 거치기 때문이다. 그래서 Elastic Search 공식 홈페이지에서도 NRT(Near Real Time)라는 표현을 쓴다.
트랜잭션(Transactio) 롤백(Rollback) 등의 기능을 제공하지 않는다.
분산 시스템 구성의 특징 때문에, 시스템적으로 비용 소모가 큰 롤백, 트랜잭션을 지원하지 않는다. 그래서 데이터 관리에 유의해야 함
일단 Elasticsearch와 관계형 DB를 비교해보자.

먼저 위의 테이블에 나오는 용어를 정리해보자.
Elasticsearch 아키텍쳐 / 용어정리
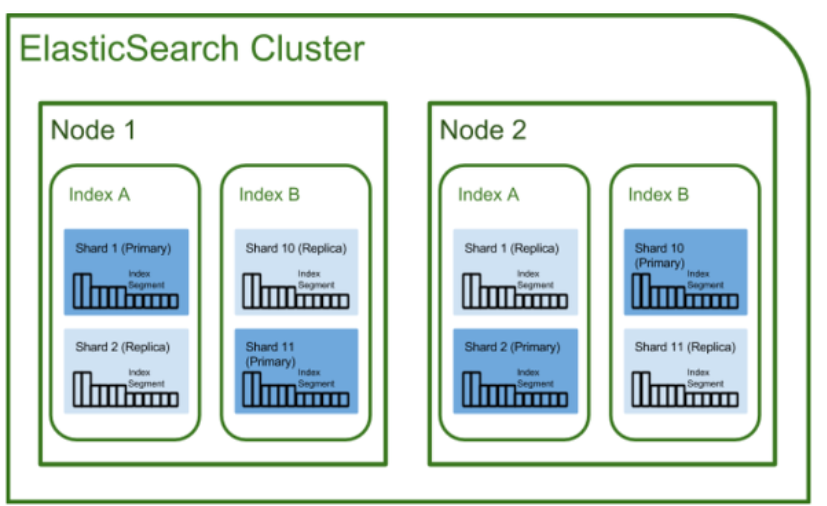
1) 클러스터(Cluster)
- 클러스터란 Elasticsearch의 가장 큰 시스템 단위를 의미하며, 최소 하나 이상의 노드로 이루어진 노드들의 집합이다. 서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지되며, 여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재할 수도 있다.
2) 노드(Node)
- Elasticsearch 를 구성하는 하나의 단위 프로세스를 의미한다. 그 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분할 수 있다.
-
master-eligible node:클러스터를 제어하는 마스터로 선택할 수 있는 노드를 말한다. 여기서 master 노드가 하는 역할은 다음과 같다
- 인덱스 생성, 삭제
- 클러스터 노드들의 추적, 관리
- 데이터 입력 시 어느 샤드에 할당할 것인지
- Data Node: 데이터와 관련된 CRUD 작업과 관련있는 노드이다. 이 노드는 CPU, 메모리 등 자원을 많이 소모하므로 모니터링이 필요하며, master 노드와 분리하는 것이 좋다.
- Ingest Node: 데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할을 한다.
- Coordination Only Node: data node와 master-eligible node의 일을 대신하는 이 노드는 대규모 클러스터에서 큰 이점이 있다. 즉 로드밸런서와 비슷한 역할을 한다.
3) 인덱스(Index) / 샤드(Shard) / 복제(Replica)
- Elasticsearch에서 index는 RDBMS에서 database와 대응하는 개념이다. 또한 shard와 replica는 Elasticsearch에만 존재하는 개념이 아니라, 분산 데이터베이스 시스템에도 존재하는 개념이다.
 파티셔닝과 샤딩의 차이
파티셔닝과 샤딩의 차이
- 파티셔닝: 하나의 데이터베이스 인스턴스에서 데이터(테이블)를 분리
- 샤딩: 데이터를 여러 데이터베이스 인스턴스로 분할
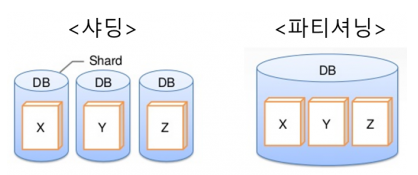
- 샤딩(sharding)은 데이터를 분산해서 저장하는 방법을 의미한다. 즉, Elasticsearch에서 스케일 아웃을 위해 index를 여러 shard로 쪼갠 것이다. 기본적으로 1개가 존재하며, 검색 성능 향상을 위해 클러스터의 샤드 갯수를 조정하는 튜닝을 하기도 한다.
- replica는 또 다른 형태의 shard라고 할 수 있다. 노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드들을 복제하는 것이다. 따라서 replica는 서로 다른 노드에 존재할 것을 권장한다. 아래 사진에서 보는 바와 같이 Replica1은 Node2에 존재하는 것을 확인할 수 있다.
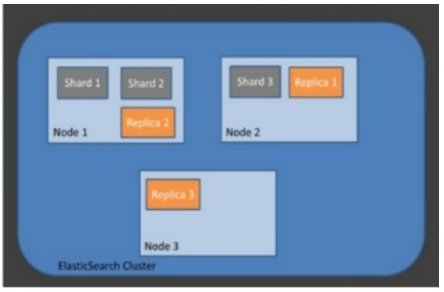
4) Elasticsearch의 특징
-
Scale out
- 샤드를 통해 규모가 수평적으로 늘어날 수 있음
-
고가용성
- Replica를 통해 데이터의 안정성을 보장
-
Schema Free
- Json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없음
-
Restful
- 데이터 CRUD 작업은 HTTP Restful API를 통해 수행하며 각각 다음과 같이 대응한다.

