스프링부트로 코로나 바이러스 트래커 만들기-02
이 프로젝트는 Java Brains 유투브 영상을 보며 공부한 것을 정리하기 위해서 남김을 알립니다. 영상과는 조금 다를 수 있음을 알립니다.
자 이제 본격적으로 서비스를 만들어보자. 아래 사진과 같이 services 패키지를 만들고 그 아래 CoronaVirusDataService 자바 클래스를 생성한다.
우리는 먼저 이전 게시물에서 보았던 Raw 데이터를 parse 해서 가져오는 것을 먼저 할 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
package io.javabrains.coronavirustracker.services;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import java.io.IOException;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
@Service
public class CoronaVirusDataService {
private static String VIRUS_DATA_URL="https://raw.githubusercontent.com/CSSEGISandData/"
+"COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/"+
"time_series_covid19_confirmed_global.csv";
@PostConstruct
public void fetchVirusData() throws IOException, InterruptedException{
HttpClient client=HttpClient.newHttpClient();
HttpRequest request= HttpRequest.newBuilder()
.uri(URI.create(VIRUS_DATA_URL))
.build();
HttpResponse<String> httpResponse=client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(httpResponse.body());
}
}
12: 서비스임을 알리는 어노테이션
15: Raw 데이터가 있는 URL를 String 변수에 담아준다.
19: @PostConstruct 어노테이션은 어플리케이션이 시작하고 스프링이 이 서비스 객체를 생성하고 나면 이 @PostConstruct 어노테이션이 있는 메소드를 자동으로 실행시켜 준다.
20: http call를 할 메소드를 작성한다. throws IOException, InterruptedException은 밑에 client.send 부분에서 send 함수를 쓰려면 exception를 받아야 하는데 그것을 catch하는 대신 throw를 한다.
22: 우리가 Http Call를 하기 위해서는 HttpClient를 사용한다.
23: 빌더 패턴을 사용가능하게 해주고 위에 선언한 VIRUS_DATA_URL 문자열을 uri로 바꾸기 위한 작업이다.
27: client를 보냄으로써 response를 받는다. 첫 번째 파라미터로는 request 그리고 두 번째로는 BodyHandler를 넣는데 이는 Body로 할 수 있는 몇 가지 기능들을 제공한다. 여기서 http Body를 문자열로 반환해주는 것이다.
29: 반환 받은 문자열을 찍어내는 역할을 한다.
자 이제 어플리케이션을 실행해서 결과가 잘 나오는지 확인해본다.
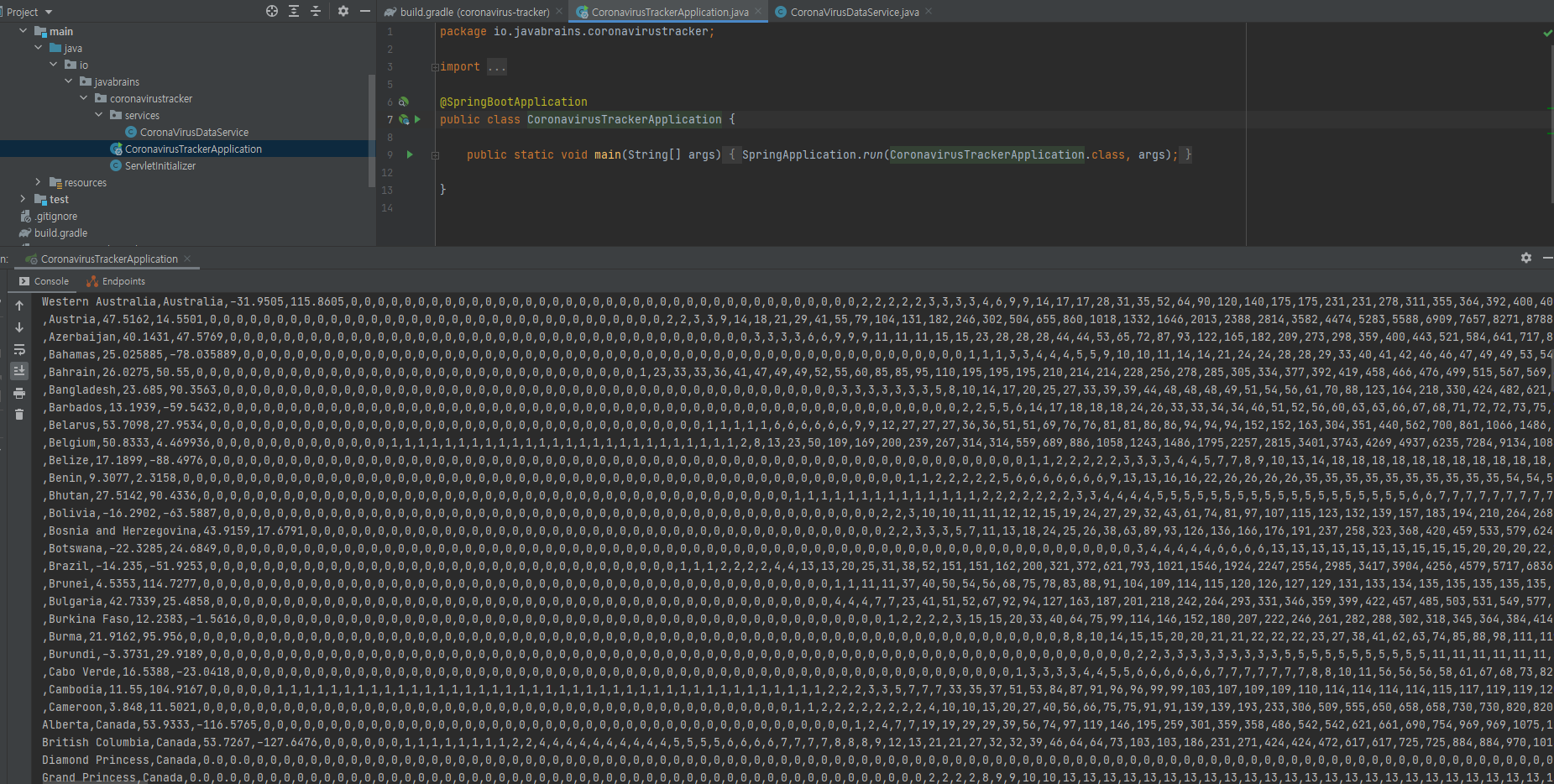
결과가 잘 나오는 것을 볼 수 있다.
이제 할 것은 이것을 parsing 하는 것이다. 코마로 분리하거나 해야 하는데 쉬운 방법이 있다.
구글에 common csv라고 치면 이러한 데이터를 parsing 해주는 라이브러리를 제공한다.
이 라이브러리를 사용해서 우리가 가지고 있는 문자열 데이터를 parsing 해보자.
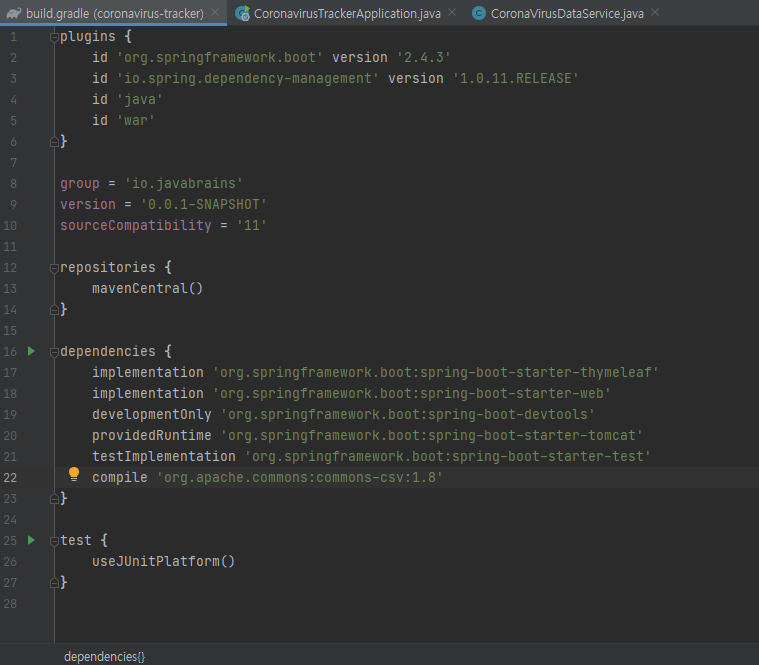
일단 이 라이브러리를 사용하기 위해 build.gradle를 수정 해야 한다.
build.gradle에
compile 'org.apache.commons:commons-csv:1.8'
를 추가하고 sync를 한다. 이 라이브러리를 이용해서 System.out.println()으로 찍어냈던 httpResponse.body()를 다른 객체로 parse 해서 사용할 수 있다. 출력한 것에서 나라, 위도, 확진자 수 등을 뽑아낼 수 있다.
이것을 하기 위해서 Commons csv 공식 홈페이지의 user guide를 참고한다.
user guide를 보다가 눈에 띄는 것이 있었다. 바로 Header auto detection이였다.
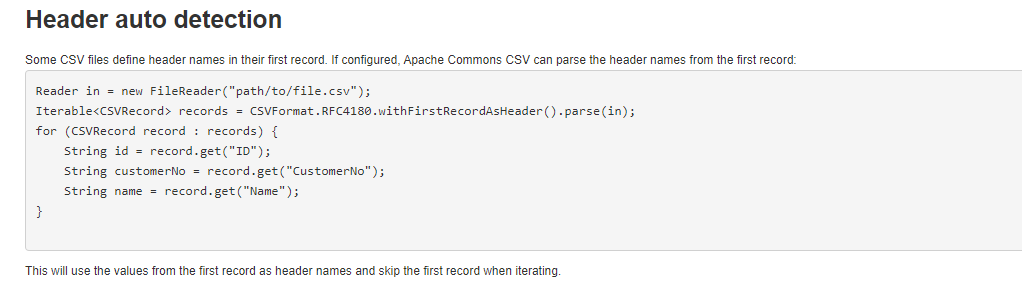
다시 Raw 데이터를 살펴보면 상단 왼쪽에 각 데이터의 컬럼이 표시되어 있는 것을 볼 수 있다.
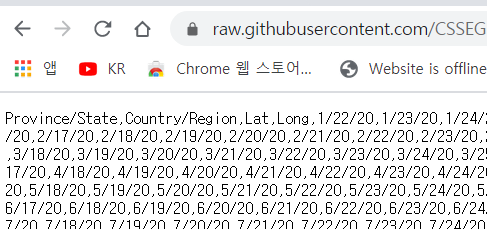
그러므로 이 header auto detection 예제를 응용해서 사용하면 편하게 데이터를 추출할 수 있다!!
이 header auto detection에 나와있는 예제를 복사해서 CoronaVirusDataService.java에 붙여놓기 해보자.
package io.javabrains.coronavirustracker.services;
import org.apache.commons.csv.CSVFormat;
import org.apache.commons.csv.CSVRecord;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import java.io.IOException;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
@Service
public class CoronaVirusDataService {
private static String VIRUS_DATA_URL="https://raw.githubusercontent.com/CSSEGISandData/"+
"COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/"
+"time_series_covid19_confirmed_global.csv";
@PostConstruct
public void fetchVirusData() throws IOException, InterruptedException{
HttpClient client=HttpClient.newHttpClient();
HttpRequest request= HttpRequest.newBuilder()
.uri(URI.create(VIRUS_DATA_URL))
.build();
HttpResponse<String> httpResponse=client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(httpResponse.body());
Iterable<CSVRecord> records = CSVFormat.RFC4180.withFirstRecordAsHeader().parse(in);
for (CSVRecord record : records) {
String id = record.get("ID");
String customerNo = record.get("CustomerNo");
String name = record.get("Name");
}
}
}
- RFC4180은 document에서 표준 쉼표 분리 값 포맷이고 빈줄은 무시한다고 일컫어져 있다.

이 RFC4180을 보기 좋게 DEFAULT라고 수정하자.
Iterable<CSVRecord> records = CSVFormat.DEFAULT.withFirstRecordAsHeader().parse(in);
그리고 ‘in’는 reader 객체이다. 우리는 reader 객체는 text를 읽을 수 있게 해주는 객체이다. 그래서 저 records 객체는 reader 객체를 반환 받는 것이다. 마지막으로 foreach문을 사용해 헤더 문자열을 사용해서 그 헤더에 해당하는 데이터를 문자열 변수에 담을 수 있는 것이다. 다시 코드를 수정해보자.
@Service
public class CoronaVirusDataService {
private static String VIRUS_DATA_URL="https://raw.githubusercontent.com/CSSEGISandData/"+
"COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/"
+"time_series_covid19_confirmed_global.csv";
@PostConstruct
public void fetchVirusData() throws IOException, InterruptedException{
HttpClient client=HttpClient.newHttpClient();
HttpRequest request= HttpRequest.newBuilder()
.uri(URI.create(VIRUS_DATA_URL))
.build();
HttpResponse<String> httpResponse=client.send(request, HttpResponse.BodyHandlers.ofString());
StringReader csvBodyReader=new StringReader(httpResponse.body());
System.out.println(httpResponse.body());
Iterable<CSVRecord> records = CSVFormat.DEFAULT.withFirstRecordAsHeader().parse(csvBodyReader);
for (CSVRecord record : records) {
String state = record.get("Province/State");
System.out.println(state);
}
}
}
16: StringReader는 String을 parse하는 리더 객체이다. 이 코드로 인해 String 객체로부터 reader 객체가 있는 것이다.
22: foreach 문으로 각 헤더의 값을 추출한다. 여기서 먼저 Province/State 헤더에 해당되는 값들을 출력해 본다.
어플리케이션을 실행해서 제대로 출력이 되나 확인한다.
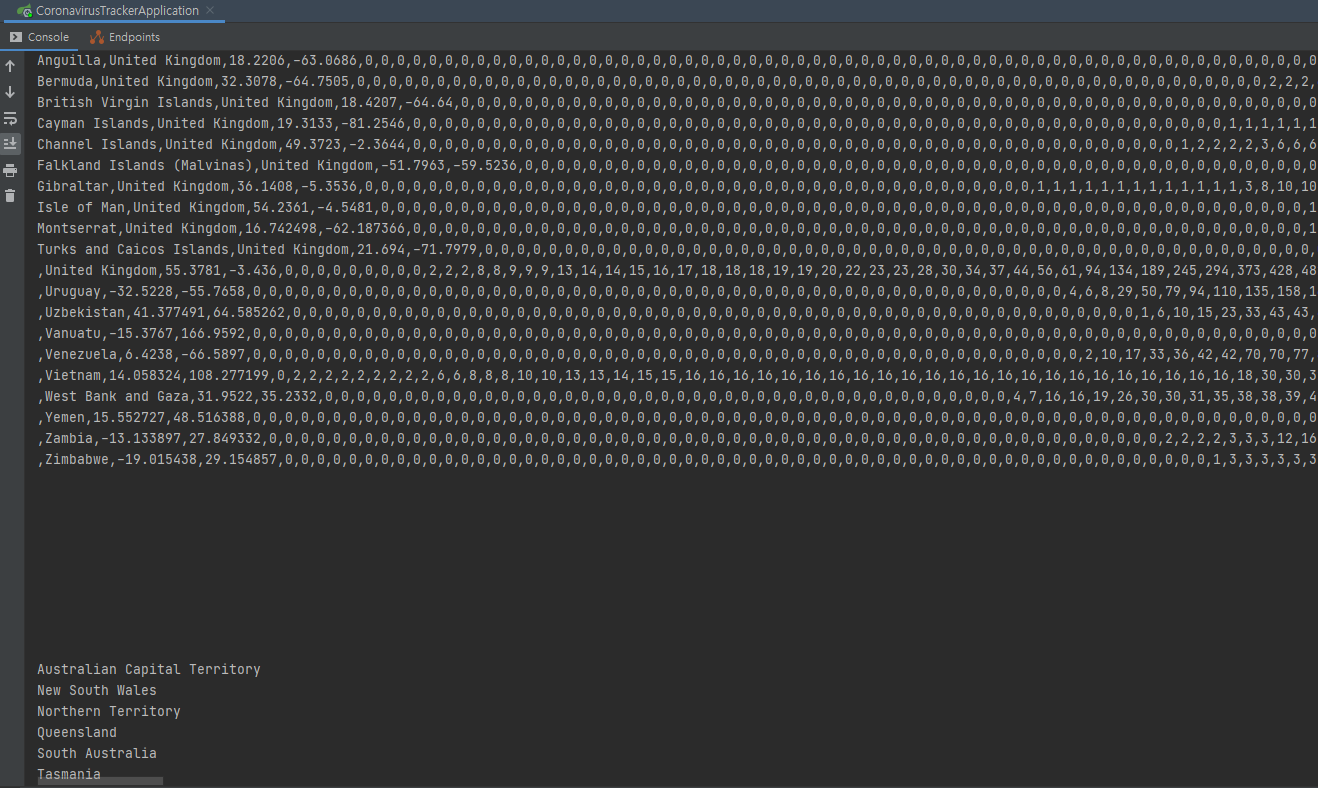
제대로 출력되고 있음을 확인할 수 있다.
생각을 좀 해볼 것이 있다. 우리가 만들고자 하는 이 코로나 바이러스 트래커는 확진자수가 매일 변경되고 업데이트 된다. 만약에 이 데이터를 우리가 한 번만 가져와서 쓰게된다면 미래 업데이트가 안 될 것이다. 그래서 우리는 매일 이 새로 업데이트 되는 csv 데이터를 우리 어플리케이션에 최신의 데이터로 업데이트 되게 만들어야 한다. 이것을 하기 위해서는 어노테이션를 하나 추가해주면 된다.
@Service
public class CoronaVirusDataService {
(...)
@PostConstruct
@Scheduled(cron="* * * * * *")
public void fetchVirusData() throws IOException, InterruptedException{
HttpClient client=HttpClient.newHttpClient();
HttpRequest request= HttpRequest.newBuilder()
.uri(URI.create(VIRUS_DATA_URL))
.build();
HttpResponse<String> httpResponse=client.send(request, HttpResponse.BodyHandlers.ofString());
StringReader csvBodyReader=new StringReader(httpResponse.body());
System.out.println(httpResponse.body());
Iterable<CSVRecord> records = CSVFormat.DEFAULT.withFirstRecordAsHeader().parse(csvBodyReader);
for (CSVRecord record : records) {
String state = record.get("Province/State");
System.out.println(state);
}
}
}
7: @Scheduled 어노테이션은 실행하고자 하는 것을 설정해둘 수 있다. * * * * * *는 각각은 왼쪽부터 초, 분, 시간, 날짜, 달, 년도를 의미한다. 그래서 이렇게 쓰면 매초 이 메소드를 실행하라는 의미가 된다.
그리고 우리가 해야 할 것은 CoronavirusTrackerApplication.java로 가서 스프링이 우리가 @Scheduled 어노테이션을 설정해놨다는 것을 알려야 한다. 그러기 위해서 @EnableScheduling를 추가한다.
package io.javabrains.coronavirustracker;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
@SpringBootApplication
@EnableScheduling
public class CoronavirusTrackerApplication {
public static void main(String[] args) {
SpringApplication.run(CoronavirusTrackerApplication.class, args);
}
}
실제로 이제 어플리케이션을 실행해보면 우리가 서비스에서 출력했던 출력문이 매초 업데이트되서 출력되는 것을 볼 수 있다. 우리가 만들고자하는 어플리케이션의 특성상 매초 업데이트되는 것은 비효율적일 것이다. 그러므로 우리가 설정했던 @Scheduled(cron=”* * * * * *”) 부분을 @Scheduled(cron=”* _ 1 _ * *”) 이렇게 수정한다. 지금 시간 부분을 1로 설정하는 것을 볼 수 있는데 이는 매일 한 번 업데이트를 한다는 뜻이다. (즉 매일 한 번 fetchVirusData() 메소드를 실행한다.)
다음 게시물에서는 이렇게 foreach문으로 각 헤더 값들을 추출한 것을 저장할 수 있는 클래스를 만들어 보겠다.
